Motif simulation explained
[1]:
import numpy as np
import seqlogo
This notebook intends to illustrate the generation of motifs and the effect of the choice of Dirichlet parameters.
Each position (letter) of a motif is sampled from a Dirichlet distribution. The Dirichlet distribution is initialized with 4 alpha parameters corresponding to A, C, G, and T bases.
[2]:
l_motif = 5
[3]:
def get_ic_logo(ppm_np: np.array):
ppm = seqlogo.Ppm(ppm_np)
print(f'The motif ppm is: {ppm}')
print(f'IC per letter: {' '.join([str(round(i,2)) for i in list(ppm.ic)])}')
print(f'IC per motif: {sum(ppm.ic):.2f}')
logo_plot = seqlogo.seqlogo(ppm, ic_scale = True, format = 'png', size = 'small')
return logo_plot
Unconstrained information content through Dirichlet parameters
This settings provide equal chances for each letter to be the main selection, but does not give very strong weight to any of them. This results in varying information content of any position of the motif.
[4]:
np.random.seed(42)
unconstrained = [1, 1, 1, 1]
motif_from_unconstr_prior = np.random.dirichlet(unconstrained, l_motif)
logo_plot = get_ic_logo(motif_from_unconstr_prior)
logo_plot
| A | C | G | T | |
|---|---|---|---|---|
| 0 | 0.082197 | 0.527252 | 0.230641 | 0.159911 |
| 1 | 0.070375 | 0.070363 | 0.024826 | 0.834435 |
| 2 | 0.161962 | 0.216972 | 0.003665 | 0.617401 |
| 3 | 0.735638 | 0.098290 | 0.082638 | 0.083434 |
| 4 | 0.179898 | 0.368931 | 0.280463 | 0.170708 |
The motif ppm is:
IC per letter: 0.31 1.11 0.64 0.75 0.07
IC per motif: 2.88
[4]:
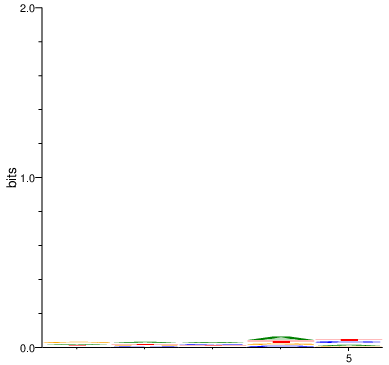
Constrained low information content
When high (>1) alpha values are provided, the Dirichlet distribution will be concentrated. This means that in the motif, each letter has about the same probability for each position. Thus, the motif has low information content.
[5]:
np.random.seed(43)
constr_low = [10, 10, 10, 10]
motif_from_constr_low_prior = np.random.dirichlet(constr_low, l_motif)
logo_plot = get_ic_logo(motif_from_constr_low_prior)
logo_plot
| A | C | G | T | |
|---|---|---|---|---|
| 0 | 0.271576 | 0.184040 | 0.325902 | 0.218483 |
| 1 | 0.334526 | 0.197765 | 0.204022 | 0.263687 |
| 2 | 0.327130 | 0.269244 | 0.196121 | 0.207505 |
| 3 | 0.372365 | 0.171653 | 0.199164 | 0.256818 |
| 4 | 0.238419 | 0.293696 | 0.151122 | 0.316763 |
The motif ppm is:
IC per letter: 0.03 0.03 0.03 0.07 0.05
IC per motif: 0.21
[5]:
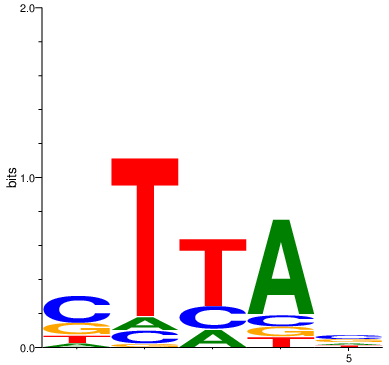
Constrained high information content
When low (<1) alpha values are given, the Dirichlet distribution will be sparse. This means that for each position in the motif a single value will get most mass while others are close to 0. Thus, the motif will have high information content.
[6]:
np.random.seed(42)
constr_high = [0.1, 0.1, 0.1, 0.1]
motif_from_constr_high_prior = np.random.dirichlet(constr_high, l_motif)
logo_plot = get_ic_logo(motif_from_constr_high_prior)
logo_plot
| A | C | G | T | |
|---|---|---|---|---|
| 0 | 1.228498e-03 | 9.987713e-01 | 1.932663e-07 | 9.883878e-12 |
| 1 | 3.711972e-02 | 8.230591e-17 | 9.628800e-01 | 2.379930e-07 |
| 2 | 8.952084e-04 | 2.978610e-02 | 9.687221e-01 | 5.966345e-04 |
| 3 | 3.098475e-02 | 8.017583e-06 | 4.237311e-01 | 5.452761e-01 |
| 4 | 1.241914e-12 | 9.794086e-01 | 6.295173e-06 | 2.058508e-02 |
The motif ppm is:
IC per letter: 1.99 1.77 1.79 0.84 1.86
IC per motif: 8.24
[6]:
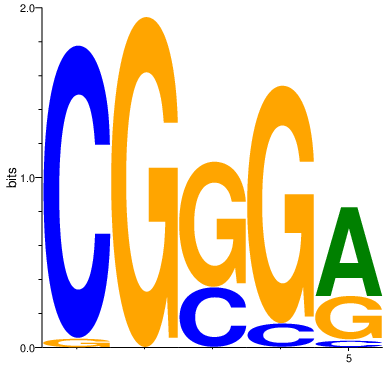
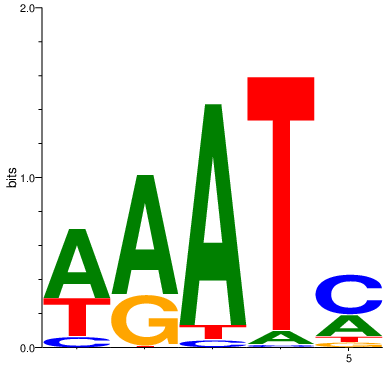
Imbalanced alphas: one (or more) letter is more probable than the rest.
In this example, higher value is given for the alpha corresponding to letter ‘A’, thus it is more likely to have the highest probability in each position. The alpha corresponding to letter ‘G’ has the lowest probability, thus it is less frequently appears in the motif as ‘C’ or ‘T’.
[7]:
np.random.seed(42)
unequal = [2, 0.5, 0.3, 0.5]
motif_from_unequal_prior = np.random.dirichlet(unequal, l_motif)
logo_plot = get_ic_logo(motif_from_unequal_prior)
logo_plot
| A | C | G | T | |
|---|---|---|---|---|
| 0 | 0.582251 | 0.090481 | 0.000497 | 0.326770 |
| 1 | 0.689308 | 0.000195 | 0.295247 | 0.015249 |
| 2 | 0.900675 | 0.038215 | 0.000634 | 0.060476 |
| 3 | 0.059368 | 0.010963 | 0.000030 | 0.929639 |
| 4 | 0.299011 | 0.545008 | 0.075405 | 0.080577 |
The motif ppm is:
IC per letter: 0.7 1.02 1.43 1.59 0.43
IC per motif: 5.16
[7]:
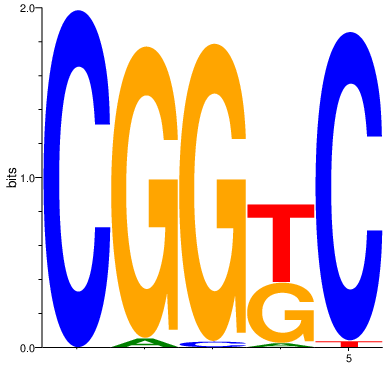
In this second example, ‘G’ and ‘C’ have higher probability than ‘A’ or ‘T’. The values are generally small, so sparsity is still achieved.
[8]:
np.random.seed(42)
gc_rich = [0.1, 0.5, 0.5, 0.1]
motif_from_gc_rich_prior = np.random.dirichlet(gc_rich, l_motif)
logo_plot = get_ic_logo(motif_from_gc_rich_prior)
logo_plot
| A | C | G | T | |
|---|---|---|---|---|
| 0 | 0.000079 | 0.964303 | 0.035618 | 6.395171e-13 |
| 1 | 0.005590 | 0.000384 | 0.994026 | 3.583746e-08 |
| 2 | 0.000012 | 0.322111 | 0.677869 | 7.818585e-06 |
| 3 | 0.000914 | 0.093587 | 0.905499 | 3.185328e-12 |
| 4 | 0.631156 | 0.054725 | 0.314119 | 4.321596e-10 |
The motif ppm is:
IC per letter: 1.78 1.95 1.09 1.54 0.83
IC per motif: 7.18
[8]: