Explanation of motif groups
Exploring the cooperative binding of transcription factors is a challenging task. InMOTIFin supports the evaluation of models for both strict grammar and soft syntax. In case of strict grammar, the multimerisation option is recommended, where new motifs are constructed by combinning existing motifs using fixed spacing. For the soft syntax task, groups are introduced.
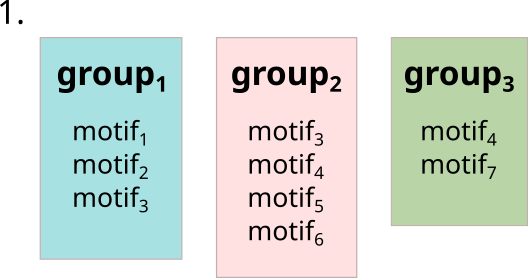
Motifs are organized into groups via random sampling (tuned by the num_groups, max_group_size, and group_size_p parameters) or by a user defined association (group_motif_assignment_file).
Each motif can belong to any number of groups.
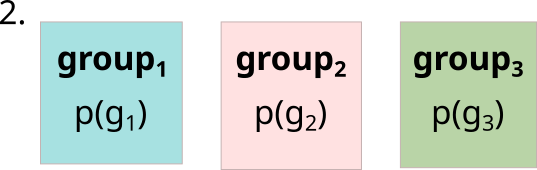
Each group has a probability of being selected (p(tx)) as a first group for a sequence.
These can be selected by inMOTIFin (tuned by the group_freq_type and group_freq_range parameters) or provided by the user as a file (group_freq_file).

If there are more than one group per sequence (num_groups_per_seq), the sampling of the groups follow a Markov chain.
That is, each group has a probability of being selected after the previous group is selected (p(tx_i| tx_(i-1))).
With the concentration_factor parameter the self-preference of a group can be adjusted, so that the second group will be the same as the first group.
The distribution of the rest of the probabilities between the rest of the groups is defined by the group_group_type parameter which can be uniform so that the rest of the groups have equal chance, or random so that they have randomly sampled chances given the already sampled group.
For more control over this setup, the user can provide a file (group_group_file).
Any number of groups can be selected for each sequence with the num_groups_per_seq parameter.

Once the groups are selected, the motifs are sampled too (with replacement).
Each motif has a probability of being sampled given the group (p(mi| tx)).
Similarly to in case of groups, these probabilities can be randomly sampled (tuned by the motif_freq_type and motif_freq_range parameters) or provided by the user (motif_freq_file).
The n_instances_per_sequence parameter control the number of motifs per sequence.
This number is equally distributed across the selected groups.
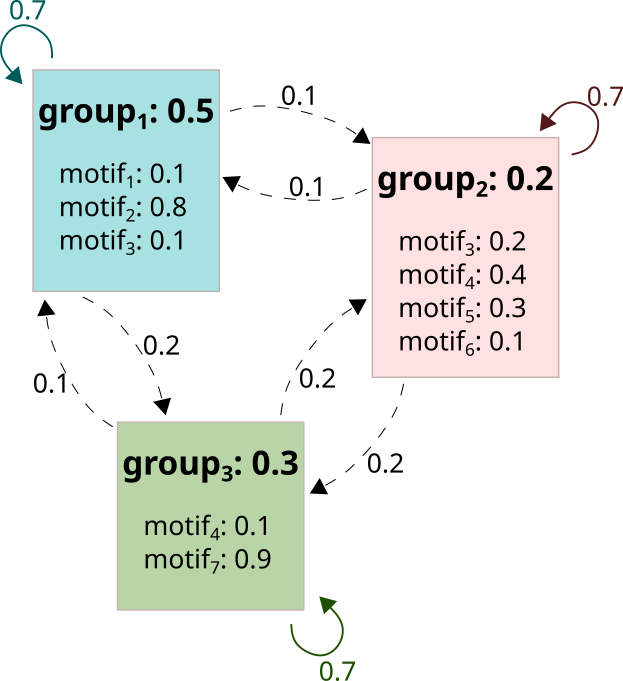
All put together, we can create the following example system. Here group1 has 50% chance of being selected first, group2 and group3 have 20% and 30%, respectively. Motif1 , motif2 , and motif3 are assigned to group1 and they have 10%, 80% and 10% chances of being sampled when group1 is selected. If there should be more than 1 group per sequence, the transition probabilities from group1 to group1 is 70%, from group1 to group3 is 20%, but from group3 to group1 is just 10%. And so on.
Usage examples
All motifs should have equal probability of appearance, independent of each other.
There are two options to achieve this, assuming we have 20 motifs and we want to select and insert 5 instances per sequence.
In the first case, we make 1 group that includes all motifs (num_groups = 1, max_group_size = 20, and group_size_p = 1).
Within the group all motif has the same probability of being selected (motif_freq_type = uniform).
When selecting a group we allow only one group per sequence and set the number of motif instances per sequence to 5 (num_groups_per_seq = 1 and n_instances_per_sequence = 5).
The other option is to create 20 groups, each of size 1 (num_groups = 20, max_group_size = 1, and group_size_p = 1).
Each group has the same probability of being selected (group_freq_type = uniform).
When selecting a group we allow only one group per sequence and set the number of motif instances per sequence to 5 (num_groups_per_seq = 1 and n_instances_per_sequence = 5).
Note that in this second case, each motif will be randomly assigned to a group, so when the analysis is repeated it is not guaranteed that the same group ID belongs to the same motif ID.
Motifs should have pairwise co-occurence probabilities
Assuming we have 4 motifs and we want to select 3 motif instances per sequence.
Each group contains only one motif as defined in the group_motif_assignment_file:
group_0 motif_0
group_1 motif_1
group_2 motif_2
group_3 motif_3
Alternatively, to produce the same table, use num_groups = 4, max_group_size = 1, group_size_p = 1 parameters.
The probabilities for selecting each group is given in the group_freq_file:
group_0 0.15
group_1 0.05
group_2 0.6
group_3 0.2
To define the transition probabilities, we use the group_group_file:
group_0 group_1 group_2 group_3
group_0 0.5 0.2 0.05 0.25
group_1 0.1 0.6 0.15 0.15
group_2 0.2 0.3 0.4 0.1
group_3 0.05 0.05 0.05 0.85
Finally, the sampling options can be set as such: 3 groups and 3 instances per sequence (num_groups_per_seq = 3 and n_instances_per_sequence = 3).
Note: here the transition probabilities are not symmetric.
Defining various group sizes and soft syntax (resembling true biological co-regulator units).
Allowing more mixing of groups and motifs and uncertainity in the selection of each better reflect biological processes.
In this example, we use a larger number of motifs (num_motifs = 20) and groups (num_groups = 10).
We assign up to 8 motifs per group (max_group_size = 8), and the expected size of each group is 5.6 (group_size_p = 0.7).
Each group has a randomly assigned probability of being selected (group_freq_type = random), and the maximum difference between a frequent group and a rare group can be 5 times (group_freq_range = 5).
Similarly, within each group motifs are also randomly assigned a probability (motif_freq_type = random) and here we allow a larger scale of differences between a frequent and a rare motif, with maximum difference of 50 times (motif_freq_range = 50).
Let’s set the probability of selecting the same group twice for a sequence to 0.7 (concentration_factor = 0.7), and the co-occurence of any two groups to have a probability between 0 and 0.3 (group_group_type = random).
During sampling, we allow up to 2 groups per sequence (num_groups_per_seq = 2), and the number of instances per sequence follow a Poisson distribution with lambda = 8 (n_instances_per_sequence_l = 8).
Since we might have quite a lot of motif instances, we can select a long background sequence (b_length = 200).
We can distribute the selected motif instances equally between two regions of the sequence using the Gaussian positioning parameter (position_type = gaussian, position_means = 50,120, position_variances = 2,10).
Note that with the Gaussian option for positioning (instances are inserted without replacing existing bases) and the Poisson option for sampling of the number of instances, the final length of the sequences will vary.