Python module
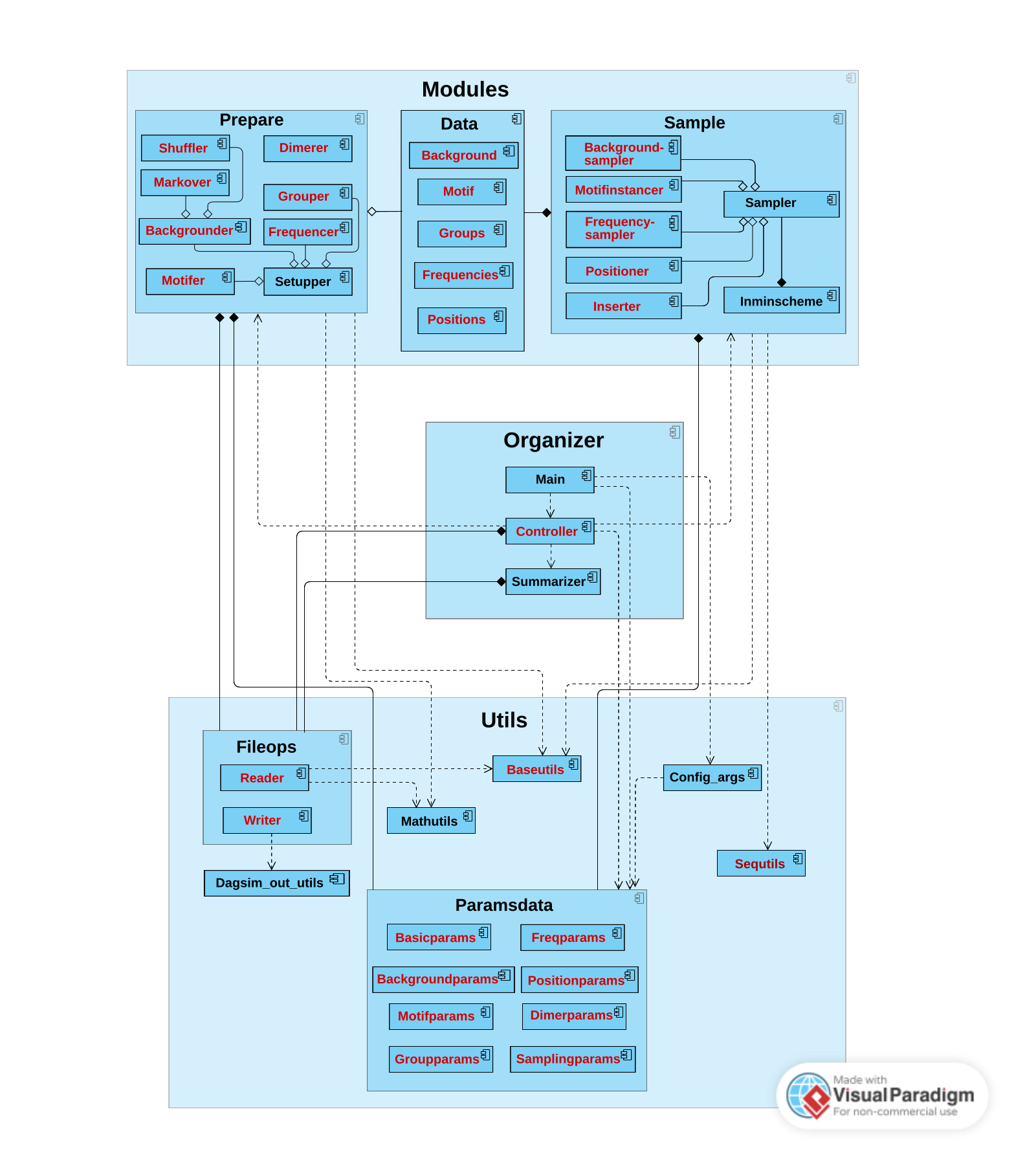
The package is following object oriented programming (OOP) principles, and it is organized into three main units: modules, organizer, and utils,
as shown on a simplified version of class diagram above.
The classes highlighted in red are available for the user.
The exception under OOP are the utils submodules, these provide only functions.
Below the exported classes are explained.
Controller class
The Controller is a main unit that talks with the Prepare and the Sample modules.
Its role is to delegate tasks from the user.
When run from the command line, it takes input from Main (which provides the command line interface and argument reading through config_args).
However, to enable usage from python, it is exposed to the user.
The simulation of motif-in-seq is provided by the run_inmotifin() function.
Simulation of motifs is provided by the create_motifs() function.
Simulation of random sequences is provided by the create_backgrounds() function.
The multimerisation can be achieved with create_multimers() function.
These functions takes Paramsdata dataclasses as their inputs, which stores the same information as would be given in the config file or command line options.
Beyond these options, the Controller class has two additional functions for more control over motif-in-seq simulation.
First, create_motif_in_seq() for adding of motifs into background sequences at specific locations.
This is different from the run_inmotifin() function because the default motif-in-seq creation is a probabilistic process and does not allow full control over which motif
gets into which sequence or which location (except central locations).
The second additional functionality, is mask_motif_in_seq() for adding background sequences to specific positions in a given sequence, thus masking existing motifs.
This is different from the ones above, in that it creates short sequences of backgrounds with the given probability for each letter and adds these into the specified locations.
Note: this does not ensure that no existing motif resembles the added masks.
Additional classes
Beyond pre-existing methods for overall insertion, inMOTIFin allows for creative combination of existing lower level functionalities.
To this end, the Motifer, MotifInstancer, Multimerer, Markover, Backgrounder, BackgroundSampler, Shuffler, Grouper, Frequencer, FrequencySampler, Positioner,
and Inserter are providing access to lower level functionalities.
Furthermore, the basic functions of onehot_to_str, create_reverse_complement, define_complementary_map_motif_array, and create_reverse_complement_motif are available.
Examples
For examples, please refer to the Python Examples page.
Detailed documentation of classes
Controller
- class inmotifin.Controller(basic_params)
Organizer of preparation and sampling
Class parameters
- reader: Reader
File reader class to read in motifs if necessary
- writer: Writer
instance of the writer class
- data_for_simulation: Dict[str, Any]
Dictionary of simulated data passed for sampling
- summary: Dict[str, Dict[str, int]]
Dictionary of summary information about the sampling
- rng: np.random.Generator
Random generator for length (uniform from integeres) and motif (Dirichlet) sampling
- create_backgrounds(background_params)
Option of creating backgrounds given input parameters
- Return type:
None
Parameters
- background_params: BackgroundParams
Dataclass storing alphabet, sequence length, sequence number, b_alphabet_prior, background_files, background_type, number_of_shuffle, and markov_order
- create_motif_in_seq(background_ids, background_dict, b_alphabets, sequence_probs, positions, motif_ids, motifs, orientations, to_replace=True)
Add motif instances to specific positions into specific backgrounds
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- background_ids: List[str]
List of background IDs in order of insertion
- background_dict: Dict[str, str]
Dictionary of backgound IDs and sequences
- b_alphabets: Dict[str, str]
Dictionary of background alphabet
- sequence_probs: Dict[str, np.ndarray]
Dictionary of background alphabet prior probabilities
- positions: List[List[Tuple[int]]]
List of list of position tuples in order of insertion per sequence and per motif in the inner list
- motif_ids: List[List[str]]
List of list of motif IDs in order of insertion per sequence and per position in the inner list.
- motifs: Motifs
Data class for motifs with names (key), PPM, alphabet and alphabet pairs
- orientations: List[List[int]]
List of list of motif instance orientations per sequence and per motif in the inner list.
- to_replace: bool
Whether to replace backgorund bases with motif instance. Alternative is to insert between existing bases. Default: True
Return
- motif_in_sequences: Dict[str, str]
Dictionary of sequence ids (with background, motif, position, and orientation) and corresponding sequences with motifs in
- probabilistic_motif_in_sequences: Dict[str, np.ndarray]
Dictionary of sequence ids (with background, motif, position, and orientation) and corresponding probabilities of letters in sequences with motifs in
- create_motifs(motif_params)
Option of creating motifs given input parameters
- Return type:
None
Parameters
- motif_params: MotifParams
Dataclass storing dirichlet_alpha, number_of_motifs, length_of_motifs_min, length_of_motifs_max, alphabet and motif_files
- create_multimers(multimer_params)
Option of creating multimers given input motifs and rules
- Return type:
None
Parameters
- multimer_params: MultimerParams
Dataclass storing motif_files, jaspar_db_version and multimerisation_rule_path
- mask_motif_in_seq(seq_with_motif, positions, mask_alphabet, mask_alphabet_prior, seq_with_motif_prob=None)
Mask motif instances with background-like sequences
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- seq_with_motif: Dict[str, str]
Dictionary of sequences with motifs corresponding to positions of masking
- positions: Dict[str, List[Tuple[int]]]
Dictionary of list of position tuples corresponding to masking per sequence and per motif in the inner list
- mask_alphabet: str
Alphabet of masking
- mask_alphabet_prior: np.array
Array of probabilties of each letter in the alphabet of masking
- seq_with_motif_prob: Dict[str, np.ndarray]
Dictionary of sequence with motifs probabilities corresponding to positions of masking. Optional. If not provided, no probabilistic output is returned (i.e., masked_probs is None)
Return
- masked_sequences: Dict[str, str]
Dictionary of sequences after motifs are masked out
- masked_probs: Dict[str, np.ndarray]
Dictionary of sequence probabilities after the motifs are masked
- run_inmotifin(motif_params, background_params, group_params, freq_params, sampling_params, positions_params)
Prepare and sample
- Return type:
None
Parameters
- motif_params: MotifParams
Dataclass storing dirichlet_alpha, number_of_motifs, length_of_motifs_min, length_of_motifs_max, alphabet and motif_files
- background_params: BackgroundParams
Dataclass storing alphabet, sequence length, sequence number, b_alphabet_prior, background_files, background_type, number_of_shuffle, and markov_order
- group_params: groupParams
Dataclass storing number_of_groups, max_group_size, group_size_binom_p and group_motif_assignment_file
- freq_params: FreqParams
Dataclass storing group_frequency_type, group_frequency_range, motif_frequency_type, motif_frequency_range, group_freq_file and motif_freq_file
- sampling_params: SamplingParams
Data class with sampling parameters
- positions_params: PositionParams
Data class with positioning parameters
- run_sampling(sampling_params, positions_params)
Run main simulation module
- Return type:
Tuple[Any]
Parameters
- sampling_params: SamplingParams
Data class with sampling parameters
- positions_params: PositionParams
Data class with positioning parameters
Return
- sampled_data: Tuple[Any]
Tuple containing dagsim_graph, data, and no_motif_seq
- save_outputs(dagsim_graph, data, no_motif_seq, no_motif_prob, to_draw)
Save outputs of simulation into files
- Return type:
None
Parameters
- dagsim_graph
Graph output from DagSim
- data: Dict[]
Dictionary of sampled data
- no_motif_seq: List[str]
List of sequences without motifs
- to_draw: bool
Whether to draw dagsim_graph or not
- setup_simulation(motif_params, background_params, group_params, freq_params)
Create data for sampling
- Return type:
None
Parameters
- motif_params: MotifParams
Dataclass storing dirichlet_alpha, number_of_motifs, length_of_motifs_min, length_of_motifs_max, alphabet and motif_files
- background_params: BackgroundParams
Dataclass storing alphabet, sequence length, sequence number, b_alphabet_prior, background_files, background_type, number_of_shuffle, and markov_order
- group_params: groupParams
Dataclass storing number_of_groups, max_group_size, group_size_binom_p and group_motif_assignment_file
- freq_params: FreqParams
Dataclass storing group_frequency_type, group_frequency_range, motif_frequency_type, motif_frequency_range, group_freq_file and motif_freq_file
- simulate_backgrounds(background_params, b_lengths=None)
Simulate backgrounds with background parameters, but can also create multiple different lengths
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- background_params: BackgroundParams
Dataclass storing alphabet, sequence length, sequence number, b_alphabet_prior, background_files, background_type, number_of_shuffle, and markov_order
- b_lengths: List[int]
List of lenght of simulated backgrounds. Order should match with b_numbers.
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
Dataclasses for input parameters
- class inmotifin.BasicParams(title, workdir=None, seed=None)
Class for keeping track of basic parameters
Class parameters
- title: str
Title of the analysis
- workdir: str
Working directory for the analysis, default is current directory. Note: it should be a relative path. Absolute paths are not supported.
- seed: int
Random seed for reproducibility, default is None
- class inmotifin.MotifParams(dirichlet_alpha=None, number_of_motifs=None, length_of_motifs_min=None, length_of_motifs_max=None, m_alphabet=None, m_alphabet_pairs=None, motif_files=None, jaspar_db_version=None)
Class for keeping track of parameters for motifs
Class parameters
- dirichlet_alpha: np.ndarray
Dirichlet prior for motif probabilities, default is uniform
- number_of_motifs: int
Number of motifs to generate, default is 10
- length_of_motifs_min: int
Minimum length of motifs, default is 5
- length_of_motifs_max: int
Maximum length of motifs, default is None, if not set all motifs will have the same length as length_of_motifs_min
- m_alphabet: str
Motif alphabet, default is “ACGT”
- m_alphabet_pairs: Dict[str, str]
Motif alphabet pairs for complementary bases, default is {“A”: “T”, “C”: “G”, “T”: “A”, “G”: “C”}
- motif_files: List[str]
List of motif file(s) to use, default is empty
- jaspar_db_version: str
Release name of JASPAR database version to use when Jaspar IDs are provided in the motif file(s) and fetched from JASPAR database via pyJASPAR. For futher information see pyJASPAR’s documentation. Example value: ‘JASPAR2024’ Default:
None
- class inmotifin.MultimerParams(motif_files, multimerisation_rule_path, jaspar_db_version=None)
Class for keeping track of parameters for multimers
Class parameters
- motif_files: List[str]
List of motif file(s) to use for multimerisation
- jaspar_db_version: str
Version of the JASPAR database to use when Jaspar IDs are provided in the motif file(s)
- multimerisation_rule_path: str
Path to the multimerisation rules file
- class inmotifin.BackgroundParams(b_alphabet=None, b_alphabet_prior=None, number_of_backgrounds=None, length_of_backgrounds_min=None, length_of_backgrounds_max=None, background_files=None, background_type=None, number_of_shuffle=None, markov_order=None, markov_n_iter=None, markov_algorithm=None, markov_seed=None)
Class for keeping track of parameters for background
Class parameters
- b_alphabet: str
Background alphabet, default is “ACGT”
- background_files: List[str]
List of background files to use, default is empty
- b_alphabet_prior: np.ndarray
Background alphabet prior probabilities, default is uniform
- number_of_backgrounds: int
Number of backgrounds to generate, default is 100
- length_of_backgrounds_min: int
Minimum length of background sequences, default is 50
- length_of_backgrounds_max: int
Maximum length of background sequences, default is None, if not set all background sequences will have the same length as length_of_backgrounds_min
- background_type: str
Options: 1) fasta_iid (fasta files are used as is - default when background_files is not None) 2) random_nucl_shuffled_only (fasta files are used, nucleotides in sequences are shuffled and only shuffled ones are used) 3) random_nucl_shuffled_addon (fasta files are used, nucleotides in sequences are shuffled and both shuffled and original ones are used) 4) iid (fasta files are ignored if provided, b_alphabet_prior specifies nucelotide probabilities - default when background_files is None) 5) markov_fit (fasta files are used to fit hidden Markov model with order specified with markov_order. Original sequences are kept) 6) markov_sim (fasta files are used to fit hidden Markov model with order specified with markov_order. New sequences are sampled)
- number_of_shuffle: int
Number of times to shuffle the backgrounds
- markov_order: int
Order of Markov model to learn from sequences (when provided) and to simulate sequences. Defaults to 0 corresponding to learning independent nucleotide frequencies.
- markov_n_iter: int
Number of iterations of Markov model to learn from sequences, default is 100
- markov_algorithm: str
Algorithm of Markov model to learn from sequences. Options: ‘viterbi’ or ‘map’. See hmmlearn 0.3.3 documentation. default is ‘viterbi’.”
- markov_seed: int
Seed for reproducibility for HMM
- class inmotifin.GroupParams(number_of_groups=None, max_group_size=None, group_size_binom_p=None, group_motif_assignment_file=None)
Class for keeping track of parameters for groups
Class parameters
- number_of_groups: int
Number of groups to generate, default is 1
- max_group_size: int
Maximum size of each group, default is infinity
- group_size_binom_p: float
Probability of success in the binomial distribution for group size, default is 1
- group_motif_assignment_file: List[str]
List of group motif assignment files, default is empty
- class inmotifin.FreqParams(group_frequency_type=None, group_frequency_range=None, motif_frequency_type=None, motif_frequency_range=None, group_group_type=None, concentration_factor=None, group_freq_file=None, motif_freq_file=None, group_group_file=None)
Class for keeping track of parameters for group and motif frequencies
Class parameters
- group_frequency_type: str
Type of group frequency distribution (“uniform”, “random”)
- group_frequency_range: int
The range of the potential differences between a frequent and a rare group
- motif_frequency_type: str
Type of motif frequency distribution (“uniform”, “random”)
- motif_frequency_range: int
The range of the potential differences between a frequent and a rare motif
- group_group_type: str
Type of group-group interaction distribution on the off-diagonal (“uniform”, “random”)
- concentration_factor: float
The preference of each groups to be selected again when selecting more than one group for insertion. Value between 0 and 1.
- group_freq_file: str
File name for group frequency data
- motif_freq_file: str
File name for motif frequency data
- group_group_file: str
File name for group-group interaction data
- class inmotifin.SamplingParams(to_draw=None, number_of_sequences=None, percentage_no_motif=None, orientation_probability=None, num_groups_per_sequence=None, motif_sampling_replacement=None, n_instances_per_sequence=None, lambda_n_instances_per_sequence=None)
Class for keeping track of parameters for sampling
Class parameters
- to_draw: bool
Whether to draw the DAG of the sampling, default is False
- number_of_sequences: int
Number of sequences to generate, default is 100
- percentage_no_motif: float
Percentage of sequences without motif, default is 0
- orientation_probability: float
Probability of orientation for the motif, default is 0.5
- num_groups_per_sequence: int
Number of groups per sequence, default is 1
- motif_sampling_replacement: bool
Whether to sample motifs from groups with replacement, default is True
- n_instances_per_sequence: int
Number of instances per sequence, default is 1
- lambda_n_instances_per_sequence: int
Lambda for the number of instances per sequence when Poisson distribution is used
- class inmotifin.PositionParams(position_type=None, position_means=None, position_variances=None, to_replace=None)
Class for keeping track of parameters for positioning
Class parameters
- position_type: str
Type of position distribution, possible values: “central”, “left_central”, “right_central”, “uniform”, “gaussian”. default is “central”
- position_means: List[int]
List of means for the position distribution, used when position_type is “gaussian”
- position_variances: List[float]
List of variances for the position distribution, used when position_type is “gaussian”
- to_replace: bool
Whether to replace the positions when generating new positions. False when position_type is “gaussian”.
Dataclasses for input for sampling
- class inmotifin.Motifs(motifs, alphabet, alphabet_revcomp_pairs)
Class for keeping track of motifs
Class parameters
- motifs: Dict[str, np.ndarray]
Dictionary of motif IDs and arrays
- alphabet: str
Alphabet of motifs
- alphabet_revcomp_pairs: Dict[str, str]
Reverse complementary pairs of alphabet, e.g. {“A”: “T”, “C”: “G”, “T”: “A”, “G”: “C”}
- motif_ids: List[str]
List of motif IDs (automatically extracted from motif dictionary)
- check_alphabet()
Make sure that the correct number of letters are provided
- class inmotifin.Backgrounds(backgrounds, b_alphabet, sequence_probs=None)
Class for keeping track of backgrounds
Class parameters
- backgrounds: Dict[str, str]
Dictionary of background IDs and sequences
- b_alphabet: str
Background alphabet, default is “ACGT”
- sequence_prob: Dict[str, np.ndarray]
Position specific background probabilities. Defaults to i.i.d
- background_ids: List[str]
List of background IDs (automatically extracted from background dictionary)
- class inmotifin.Groups(groups)
Class for keeping track of groups
Class parameters
- groups: Dict[str, List[str]]
Dictionary of group IDs and the motifs within each group
- class inmotifin.Frequencies(group_freq, motif_freq_per_group, group_group_transition_prob)
Class for keeping track of frequencies
Class parameters
- num_groups: int
Number of groups
- group_freq: Dict[str, float]
Dictionary of group IDs and their expected occurrence frequencies
- motif_freq_per_group: pd.DataFrame
Dataframe of expected frequencies of motifs per group
- group_group_transition_prob: pd.DataFrame
Dataframe of expected transition probabilities of group pairs
Simulating data
- class inmotifin.Motifer(params, rng, reader, writer)
Class to generate and select sequence motifs
Class parameters
- title: str
Title of the analysis
- params: MotifParams
Dataclass storing dirichlet_alpha, number_of_motifs, length_of_motifs_min, length_of_motifs_max, alphabet and motif_files
- rng: np.random.Generator
Random generator for length (uniform from integeres) and motif (Dirichlet) sampling
- reader: Reader
File reader class to read in motifs if necessary
- writer: Writer
instance of the writer class
- motifs: Motifs
Data class for motifs with names (key) and PPM, alphabet and ids
- motif_lengths: List[int]
The number of positions in each motif
- create_motifs()
Controller function to read motifs from file or jaspar ID if file not available or simulate if no file nor ID are available
- Return type:
None
- get_pwms()
Get PWMs of motifs
- Return type:
Dict[str,ndarray]
Return
- motif_dict: Dict[str, np.ndarray]
Dictionary with the motif IDs and PWMs
- read_motifs()
Read motifs from files in csv, jaspar or meme format
- Return type:
None
- simulate_motifs()
Generate motifs with name and PPM
- Return type:
None
- class inmotifin.Multimerer(params, reader, writer, rng)
Prepare multimers given two motifs and a distance
Class parameters
- params: MultimerParams
Dataclass storing motif_files, jaspar_db_version and multimerisation_rule_path
- multimer_rules: Dict[str, Tuple[List[str], List[int]]]
Dictionary of IDs and tuple of motif ID and pairwise distances
- motifs: Motifs
Data class for motifs with names (key) and PPM, alphabet and ids
- multimers: Motifs
Data class for multimer motifs with names (key) and PPM, alphabet and ids
- reader: Reader
File reader class to read in motifs and distances
- writer: Writer
instance of the writer class
- rng: np.random.Generator
Random generator for adding epsilon to the equal probability of empty positions
- create_a_multimer(motifs, distances, weights=None, random_variance=0.01)
Based on motifs and a rule create a multimer
- Return type:
ndarray
Parameters
- motifs: List[np.ndarray]
List of motifs that are part of the multimer
- distances: List[int]
List of distances in between motifs that are part of the multimer
- weights: List[float]
List of weigths for each motifs that are part of the multimer
- random_variance: float
Magnitude of gaussian variance at the in-between positions
Return
- multimer: np.ndarray
Multimer motif in numpy array format
- create_multimers(multimer_rules, random_variance=0.01)
Fnction to assemble multimers
- Return type:
None
- get_multimers()
Getter for multimers
- Return type:
Return
- multimers: Motifs
Data class for multimer motifs with names (key) and PPM, alphabet and ids
- main()
Main function to read, assemble and save multimers
- Return type:
None
- read_motifs()
Read motifs from files in csv, jaspar or meme format
- Return type:
None
- read_multimer_rules()
Read tsv of multimerisation rules
- Return type:
Tuple[str,Tuple[List[str],List[int],List[float]]]
- save_multimers()
Save multimers in meme format
- Return type:
None
- class inmotifin.Backgrounder(params, reader, writer, rng)
Class to generate or read background sequences
Class parameters
- title: str
Title of the analysis
- params: BackgroundParams
Dataclass storing alphabet, sequence length, sequence number, b_alphabet_prior, order, background_files, background_type, number_of_shuffle, and markov_order
- backgrounds: Backgrounds
Data class for backgrounds
- shuffler: Shuffler
Class for shuffling background sequence
- reader: Reader
File reader class to read in sequences if necessary
- writer: Writer
instance of the writer class
- rng: np.random.Generator
Random generator for sampling letters
- assign_iid_probs(backgrounds)
Assign position probabilities to sequences based on alphabet priors
- Return type:
Dict[str,ndarray]
Parameters
- backgrounds: Dict[str, str]
Dictionary with the background IDs and sequences
Return
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- create_backgrounds()
Controller function to read backgrounds or simulate if no file available
- Return type:
None
- fit_markov(sequences)
Fit hidden Markov model on sequences to get position specific letter probabilities
- Return type:
Dict[str,ndarray]
Parameters
- sequences: Dict[str, str]
Dict of input sequences
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- get_backgrounds()
Getter for simulated backgrounds
- Return type:
Return
- backgrounds: Backgrounds
Backgrounds dataclass with sequence and metadata
- get_backgrounds_seq()
Getter for simulated backgrounds
- Return type:
Dict[str,str]
Return
- backgrounds_seq: Dict[str, str]
Dictionary with the background IDs and sequences
- markov_backgrounds()
Generates a dictionary of sequences with ids
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences and IDs
- background_probs: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- read_backgrounds()
Reads sequences into a dictionary of sequences with ids and dictionary of sequence probabilities (iid)
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences and IDs
- background_probs: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- shuffle_backgrounds()
Shuffle available backgrounds thus generate new ones
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- backgrounds: Dict[str, str]
Dictionary with the background IDs and sequences
Return
- backgrounds_seq: Dict[str, str]
Dictionary with the shuffled background IDs and sequences
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- simulate_iid_backgrounds(b_lengths=None)
Generates a dictionary of random sequences within which each position is iid, and assignes IDs for each sequence
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- b_lengths: List[int]
List of lenght of simulated backgrounds. If None, sampled with b_length_min and b_length_max fetched from params data
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- simulate_markov(sequences)
Simulate background using Markov model
- Return type:
Tuple[Dict[str,str],Dict[str,ndarray]]
Parameters
- sequences: Dict[str, str]
Dict of input sequences
Return
- backgrounds: Dict[str, str]
Dictionary of background sequences
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- class inmotifin.Markover(alphabet, order, n_iter, rng, algorithm='map', seed=123)
Class to learn Markov model from input sequences
Class parameters
- algorithm: str
Name of the algorithm to be used in HMM: map (default) or viterbi
- alphabet_idx_map: Dict[str, int]
Map alphabet characters to integers
- idx_alphabet_map: Dict[int, str]
Map integers to alphabet characters
- model: hmm.CategoricalHMM
HMM model to fit and sample from
- rng: np.random.Generator
Random generator for length (uniform from integers)
- calc_position_probabilities(sampled_states)
Given a sequence and a trained model, calculate emission probabilities for each position
- Return type:
ndarray
Parameters
- sampled_states: List[int]
List of sampled states (in a single sequence)
Return
- _np.ndarray
Numpy array of probabilities of each letter per each position
- fit_model(sequences)
Function to fit model on sequences
- Return type:
None
Parameters
- sequences: List[str]
List of sequences to fit model on
- get_probabilities(sequences)
Assign position specific probabilities for the input sequences based on fitted model
- Return type:
Dict[str,ndarray]
Parameters
- sequences: Dict[str, str]
Dictionary of background sequences
Return
- backgrounds_prob: Dict[str, np.ndarray]
Dictionary of background sequence probabilities of letters in each position
- get_str_sequence(sampled_seq)
Convert sampled sequence to string
- Return type:
str
Parameters
- sampled_seq: np.ndarray
A list of sampled integers as characters per position
Return
- sampled_str: str
Character string representation of the sampled sequence
- sample_from_model(len_sample)
Sample sequence from fitted model
- Return type:
Tuple[List[int],List[List[int]]]
Parameters
- len_sample: int
Length of the sequence to be sampled
Return
- sampled_seq: List[int]
List of sampled sequences
- sampled_states: List[List[int]]
List of sampled stated per position
- sample_str_and_prob(len_seq_min, len_seq_max, num_seq)
Sample a sequence and its positional probabilities
- Return type:
Tuple[List[str],List[List[ndarray]]]
Parameters
- len_seq_min: int
Minimum length of the sequence to be sampled
- len_seq_max: int
Maximum length of the sequence to be sampled. If None, it is set equal to len_seq_min. Defaults to None
- num_seq: int
Number of sequences to generate
Return
- seq_str: List[str]
List of sampled sequences
- seq_probs: List[List[np.ndarray]]
List of position-specific letter probabilities
- class inmotifin.Shuffler(number_of_shuffle, rng)
Class to shuffle background sequences
Class parameters
- number_of_shuffle: int
The number of new sequences to be created from an existing one by shuffling it
- rng: np.random.Generator
Random generator for permuting letters
- shuffle_seq_random_nucleotide(backgrounds)
Randomly shuffle each letter in the previously read sequences, adding new sequence entries
- Return type:
Dict[str,str]
Parameters
- backgrounds: Dict[str, str]
Dictionary of backgrounds to update
Return
- shuffled: Dict[str, str]
Dictionary of shuffled backgrounds
- class inmotifin.Grouper(params, motif_ids, reader, writer, rng)
Class to select motif-group
Class parameters
- title: str
Title of the analysis
- params: groupParams
Dataclass storing number_of_groups, max_group_size, group_size_binom_p and group_motif_assignment_file
- motif_ids: List[str]
Motif IDs
- reader: Reader
File reader class to read in sequences if necessary
- writer: Writer
instance of the writer class
- groups: groups
groups with names (key) and list of motifs within them
- rng: np.random.Generator
Random generator for group sizes and motif sampling
- assign_motifs_to_groups(group_sizes)
Assign each motif to a group
- Return type:
Dict[str,List[str]]
Parameters
- group_sizes: List[int]
List of sizes of groups
Return
- motif_group_membership: Dict[str, List[str]]
Dictionary of the group IDs and the list of motifs within
- create_groups()
Create group sizes and memberships
- Return type:
None
- get_groups()
Getter for groups
- Return type:
Return
- groups: groups
groups with names (key) and list of motifs within them
- membership_assignment(assignees, group_sizes)
General function to assign membership of one list to another
- Return type:
Dict[str,List[str]]
Parameters
- assignees: Set[str]
Set of instances that should be assigned to groups
- group_sizes: List[int]
List of sizes of groups
Return
- group_assignee_membership: Dict[str, List[str]]
Dictionary of memberships of assignees within groups Key: group id, Value: list of the id of the asignees
- read_groups()
Read in group sizes and memberships from file
- Return type:
None
- select_group_sizes_binomial()
Helper function to select sizes of groups
- Return type:
List[int]
Return
- adjusted_sizes: List[int]
List of sizes of groups
- simulate_groups()
Simulate group sizes and memberships
- Return type:
None
- class inmotifin.Frequencer(params, groups, reader, writer, rng)
Class to generate motif and group background frequencies, that is the selection probability for each group and motif within
Class parameters
- title: str
Title of the analysis
- params: FreqParams
Dataclass storing group_frequency_type, group_frequency_range, motif_frequency_type, motif_frequency_range, group_freq_file and motif_freq_file
- groups: groups
The groups with ids and assigned motifs
- num_groups: int
Number of groups
- reader: Reader
File reader class to read in sequences if necessary
- writer: Writer
instance of the writer class
- frequencies: Frequencies
Data class for frequencies
- rng: np.random.Generator
Random generator for random frequency sampling
- assign_frequencies()
Read in or simulate group and motif frequencies
- Return type:
None
- assign_group_frequencies()
Simulate group frequencies
- Return type:
Dict[str,float]
Return
- group_freq: Dict[str, float]
Dictionary of group IDs and their expected occurrence frequencies
- assign_group_group_trans_probs()
Simulate the probability of selecting groupX given previously selected groupY
- Return type:
DataFrame
Return
- group_group_transition_prob: pd.DataFrame
Pandas dataframe of co-occurrences of group pairs
- assign_motif_frequencies()
Simulate motif frequencies within groups
- Return type:
DataFrame
Return
- motif_group_df: pd.DataFrame
Pandas dataframe of motif frequencies per group
- get_frequencies()
Getter for group and motif frequencies
- Return type:
Return
- frequencies: Frequencies
Data class for frequencies
- pairs_random(remaining_prob)
Creating a matrix of group-group and their transition probability: off-diagonals are random but rows sum to 1
- Return type:
ndarray
Parameters
- remaining_prob: float
The probability remaining after assigning self transition
Return
- group_prob_arr: np.ndarray
Array containing probabilities for group transition
- pairs_uniform(remaining_prob)
Creating a matrix of group-group and their transition probabilities: off-diagonals are uniform
- Return type:
ndarray
Parameters
- remaining_prob: float
The probability remaining after assigning self transition
Return
- group_prob_arr: np.ndarray
Array containing probabilities for group transition
- read_group_freq()
Read in group frequencies
- Return type:
Dict[str,float]
Return
- group_freq: Dict[str, float]
Dictionary of group IDs and their expected occurrence frequencies
- read_group_group_trans()
Read in group group transitions
- Return type:
DataFrame
Return
- group_group: pd.DataFrame
Pandas dataframe of co-occurrences of group pairs
- read_motif_freq_per_group()
Read in motif frequencies
- Return type:
DataFrame
Return
- motif_freq: pd.DataFrame
Motif frequencies per group from file
- simulate_background_freq(freq_type, freq_range, ids)
Simulate background frequencies
- Return type:
Dict[str,float]
Parameters
- freq_type: str
Way to generate frequencies. Currently random and uniform are supported. Random refers to random sampling from a range of probabilities given freq_range. Uniform refers to assigning equal probabilities to all items.
- freq_range: int
The expected max difference between an unlikely and a likely event . E.g. if set to 100, a low probability event can be 100x less likely than a high probability one
- ids: List[str]
The IDs of the items to assign frequency to
Return
- background_freq: Dict[str, float]
Probability assigned to each element of the given ids
- simulate_background_freq_random(difference_width, ids)
Simulate background frequencies random uniform
- Return type:
Dict[str,float]
Parameters
- difference_width: int
The expected max difference between an unlikely and a likely event . E.g. if set to 100, a low probability event can be 100x less likely than a high probability one
- ids: List[str]
The IDs of the items to assign frequency to
Return
- background_freq: Dict[str, float]
Probability assigned to each element of the given ids
Sampling from data
- class inmotifin.MotifInstancer(motifs, rng)
Class to take in motifs and generate the required number of instances
Class parameters
- motifs: Motifs
Data class for motifs with names (key) and PPM
- rng: np.random.Generator
Random generator for multinomial instance sampling
- get_one_new_instance(motif_index)
Generate exactly one new motif instance
- Return type:
str
Parameters
- motif_index: str
ID of the motif from which an instance to be sampled
Return
- instance_str: str
Sequence of a motif instance
- orient_motif(current_instance, orientation)
Reverse complementing an instance as necessary
- Return type:
str
Parameters
- current_instance: str
String of a motif instance
- orientation: int
0 or 1, where 0 means keeping the orientation and 1 means reverse complementing the motif instance.
Return
- oriented_instance: str
Sequence of an oriented instance
- class inmotifin.BackgroundSampler(backgrounds, rng)
Class to support sampling functions
Class parameters
- backgrounds: Backgrounds
Data class for backgrounds
- rng: np.random.Generator
Random generator for selecting a background
- get_b_alphabet()
Get background alphabet
- Return type:
str
- get_b_alphabet_prior()
Get background alphabet prior
- Return type:
ndarray
- get_background_ids(num_sample)
Get a list of selected background sequence IDs
- Return type:
List[str]
Parameters
- num_sample: int
Number of samples to select
Return
- selected_ids: List[str]
List of sequence IDs
- get_backgrounds(num_backgrounds)
Get a list of backgrounds and their probabilties may contain duplicated entries
- Return type:
Tuple[List[str],List[ndarray]]
Parameters
- num_backgrounds: int
Number of requested backgrounds
Return
- selected_backgrounds: List[str]
List of non-unique comma separated background IDs and sequences
- selected_b_probs: List[np.ndarray]
List of corresponding sequence probabilities
- get_single_background(selected_id)
Get a selected background sequence
- Return type:
Tuple[str,ndarray]
Parameters
- selected_id: str
The name of the selected sequence
Return
- bckg_seq: str
A sequence given the selected_id
- bckg_prob: np.ndarray
A corresponding matrix of probabilities per position per letter
- class inmotifin.FrequencySampler(frequencies, num_groups_per_seq, rng)
Class to select motif based on its background frequencies
Class parameters
- frequencies: Frequencies
Frequencies data class including probabilities of groups and motifs within them
- num_groups_per_seq: int
Number of groups to select in total
- rng: np.random.Generator
Random generator for sampling
- select_groups()
Select groups based on their frequency and transition probability in a Markov chain fashion: the selection of the next group depends on the previous selected one given the group_group_transition_prob matrix. The first group is selected from the base group frequency list
- Return type:
List[str]
Return
- selected_ids: List[str]
List of selected group ids
- select_motifs_from_groups(group_ids, num_instances_per_seq, w_replacement=True)
Select motifs from given groups. Equal number of motifs from each group. If cannot equally assign, loops through groups and picks one each until no more motifs
- Return type:
List[str]
Parameters
- group_ids: List[str]
List of selected group ids
- num_instances_per_seq: int
Number of motifs to select (per sequence)
- w_replacement: bool
Whether to select motifs from groups with replacement. Note, if more motifs are requested than available in a group, replacement will be used regardless of this parameter.
Return
- selected_motifs: List[str]
List of selected motif IDs
- class inmotifin.Positioner(params, selected_instances, seq_length, reader, rng)
Class to select positions where motif instances are to be inserted
Class parameters
- params: PositionParams
Dataclass storing position_type, position_means, position_variances, and to_replace (insertion type)
- motif_lengths: List[int]
List of the length of the motif instances to be inserted
- seq_length: int
Length of the background sequence
- positions: Positions
Start and end indeces where the motif instance should be inserted
- reader: Reader
Fileops class with reading functionalities
- rng: np.random.Generator
Random generator for length (uniform from integeres)
- check_central_positions(central_position)
Assert that the start and end positions are within bounds
- Return type:
None
Parameters
- central_position: List[Tuple[int]]
List of positions that should be within the bounds of the length of the background
- check_lengths()
Helper function to check if motif instances would fit into background sequence used when the motifs are replacing background bases
- Return type:
None
- check_overlap(current_positions, start_idx, end_idx)
Helper function to assess overlapping motifs
- Return type:
bool
Parameters
- current_positions: List[Tuple[int]]
Current list of positions
- start_idx: int
Start index of the motif
- end_idx:int
End index of the motif
Return
- _: bool
True if there is overlap
- get_positions()
Getter for positions class
- Return type:
Return
- positions: Positions
Dataclass of the start and end values of the selected positions
- get_to_replace()
Getter for to_replace parameter
- Return type:
bool
Return
- _: bool
True if the motif instances should replace background bases
- select_central_position()
Calculate central position at the middle of the motif
- Return type:
None
- select_gaussian_inserted()
Sample positions following Gaussian distribution centered around k positions. Only for inserting motif without replacing background bases.
- Return type:
None
- select_leftcentral_position()
Calculate central position at the left side of the motif
- Return type:
None
- select_positions()
Main function to position selector
- Return type:
Return
- positions: Positions
Dataclass of selected start and end positions
- select_positions_inserted()
Generate positions within background sequence to insert motif instances, insert motif instances without replacing background bases. Note: both positions are the start as insertion is non replacing
- Return type:
None
- select_positions_replace()
Generate positions within bacgkround sequence to insert motif instances, ensure that motif instances are not overlapping each other, motif instances replacing background bases.
- Return type:
None
- select_rightcentral_position()
Calculate central position at the right side of the motif
- Return type:
None
- class inmotifin.Inserter(to_replace)
Class to add motif instance(s) to sequences
Class parameters
- to_replace: bool
Whether the motif instance replaces background bases, alternative is to insert by extending the bakground
- add_single_instance(sequence, motif_instance, position)
Adds a given motif_instance in a background sequence by replacing existing bases or by increasing the length
- Return type:
str
Parameters
- sequence: str
String of the sequence used as background
- motif_instance: str
motif instance to insert
- position: int
the start location where the motif to be inserted within the background sequence
Return
- new_sequence: str
Sequence with instance inserted
- add_single_motif_probabilities(sequence, motif, position)
Adds a given motif in a background probability array by replacing existing bases or by increasing the length
- Return type:
ndarray
Parameters
- sequence: np.ndarray
Letter probabilities of the sequence used as background
- motif: np.ndarray
PWM to insert
- position: int
the start location where the motif to be inserted within the background sequence
Return
- new_sequence: np.ndarray
Letter probabilities of sequence with motif inserted
- create_insert_positions(positions, motif_instances=None, motif_ids=None)
Reverse the positions to insert from the end when bases are not replaced to avoid overwriting the positions of the already inserted motifs. Adjusts the motif list to match the lengths
- Return type:
Tuple[List[Tuple[int]],List[str],List[str]]
Parameters
- positions: List[Tuple[int]]
List of (start, end) position tuples.
- motif_instances: List[str]
List of motif instance sequences
- motif_ids: List[str]
List of motif IDs to insert
Return
- positions: List[Tuple[int]]
List of (start, end) position tuples in correct order.
- motif_instances: List[str]
List of motif instance sequences in correct order
- motif_ids: List[str]
List of motif IDs to insert in correct order
- generate_motif_in_sequence(sequence, motif_instances, positions)
Function to insert all motif_instances into a background
- Return type:
str
Parameters
- sequence: str
String of a background sequence to insert motif_instances to
- motif_instances: List[str]
List of motif instance sequences
- positions: List[Tuple[int]]
List of (start, end) position tuples.
Return
- motif_in_sequence: str
Sequence with motif instances inserted
- generate_probabilistic_motif_in_sequence(b_alphabet, sequence_prob, motifs, motif_ids, orientation_list, positions)
Function to insert motifs into a probabilistic background sequence
- Return type:
ndarray
Parameters
- b_alphabet: str
Background alphabet, default is “ACGT”
- sequence_prob: np.ndarray
Background sequence position-specific probabilities
- motifs: Motifs
Data class for motifs with names (key), PPM, alphabet and alphabet pairs
- motif_ids: List[str]
List of motif IDs to insert
- orientations: List[int]
Mask for instances. List of 0s and 1s, where 0 means keeping the orientation, 1 means reverse complementing the motif instance.
- positions: List[Tuple[int]]
List of (start, end) position tuples.
Return
- probabilistic_motif_in_sequence: np.ndarray
Letter probabilities in sequence with motif instances inserted
Utility classes
- class inmotifin.Reader
IO methods for reading motifs, groups and backgrounds
- convert_jaspardict_to_ppm(pyjaspar_out)
Convert dictionary of pyjaspar to numpy array
- Return type:
ndarray
Parameters
- pyjaspar_out: Dict[str, List[float]]
Dictionary in the form of {‘A’: [1,1,1], ‘C’:[1,1,1], etc}
Return
- motif_ppm: np.ndarray
Motif as ppm in numpy array format (col: ACGT, row: value per position)
- fetch_motif_from_jaspar(mfile, jaspar_db_version='JASPAR2024')
Fetch motifs from JASPAR database
- Return type:
Tuple[Dict[str,ndarray],str]
Parameters
- mfile: str
List of motif JASPAR IDs of interest
- jaspar_db_version: str
Version of the JASPAR database. Defaults to JASPAR2024
Return
- motifs: Dict[str, np.ndarray]
Motifs with ID and ppm
- alphabet: str
Letters of the input alphabet
- read_fasta(fasta_files)
Read fasta files into a dictionary of identifiers and sequences
- Return type:
Dict[str,str]
Parameters
- fasta_files: List[str]
Path to the files
Return
- sequences: Dict[str, str]
Dictionary of identifiers and sequences
- read_in_motifs(motif_files, jaspar_db_version)
Select reader by identifying the format and read in motif
- Return type:
Tuple[Dict[str,ndarray],str]
Parameters
- motif_files: List[str]
List of files with motifs in jaspar or meme format
- jaspar_db_version: str
Version of the JASPAR database. Used when motif IDs are specified.
Return
- my_motifs: Dict[str, np.ndarray]
Dictionary of motifs with ID as key and ppm as value
- alphabet: str
Alphabet read from file. Only one is supported per run.
- read_jaspar(mfile)
Read motif in jaspar format with Bio.motifs
- Return type:
Tuple[Dict[str,ndarray],str]
Parameters
- mfile: str
Path to the file
Return
- motifs_in: Dict[str, np.ndarray]
Motifs with ID and ppm
- alphabet: str
Letters of the input alphabet
- read_meme(mfile)
Read motif in meme
- Return type:
Tuple[Dict[str,ndarray],str]
Parameters
- mfile: str
Path to the file
Return
- motifs_in: Dict[str, np.ndarray]
Motifs with ID and ppm
- alphabet: str
Letters of the input alphabet
- read_motif(mfile, jaspar_db_version=None)
Read motif from inferred format
- Return type:
Dict[str,ndarray]
Parameters
- mfile: str
Path to the file
- jaspar_db_version: str
Version of the JASPAR database. Used when motif IDs are specified. Defaults to None.
Return
- motifs_in: Dict[str, np.ndarray]
Motifs with ID and PWM
- read_multimerisation_tsv(multimerisation_rule_path)
Read tsv with two (optionally three) columns of comma separated lists (motif id, distance and weights): List[str] and List[int] and List[float]
- Return type:
Dict[str,Tuple[List[str],List[int],List[float]]]
Parameters
- multimerisation_rule_path: str
Path to a tsv with (optionally three) columns of comma separated lists (motif id, distance and weights): List[str] and List[int] and List[float]
Return
- multimer_rules: Dict[str, Tuple[List[str], List[int], List[float]]]
Dictionary of IDs and tuple of motif ID and pairwise distances
- read_tsv_to_pandas(pandas_dftsv_path)
Read in tsv exported by pandas or tsv looking like that
- Return type:
DataFrame
Parameters
- pandas_dftsv_path: str
Path to a TSV file with first column the index valued for pandas dataframe
Return
- df_from_tsv: pd.DataFrame
Pandas dataframe from the provided TSV file
- read_twocolumn_tsv(twocolumns_tsv_path)
Read tsv of two columns, second is a comma separated list or a single value
- Return type:
Dict[str,List[str]]
Parameters
- twocolumns_tsv_path: str
Path to a TSV file with two columns. First column must have a single value.
Return
- two_columns: Dict[str, List[str]]
Dictionary of the values of the two columns, where the key is the value of the first column and the value of the dictionary is the value(s) of the second column.
- class inmotifin.Writer(workdir, title)
IO methods for saving simulated motifs, groups and backgrounds
Class parameters
- title: str
Title of the analysis
- workdir: str
Directory of the analysis
- outfolder: str
A subfolder in the workdir with the same name as the title
- data_to_bed(dagsim_data)
Save bed files with motif coordinates.
- Return type:
None
Parameters
- dagsim_data: Dict[str, Any]
dictionary from the Dagsim output
- dict_of_dict_to_json(counts_dict, filename)
Save counts dictionary to json
- Return type:
None
Parameters
- counts_dict: Dict[str, Dict[str, int]]:
Dictionary of names, values and counts
- filename:
Output file name prefix. Json will be appended and saved to outfolder with title prefix.
- dict_to_fasta(seq_dict, filename)
Export data in list format to a fasta file. One entry = one line
- Return type:
None
Parameters
- seq_dict: Dict[str, str]:
Sequence info and actual sequence in a dictionary format
- filename:
Output file name prefix. Fa will be appended and saved to outfolder with title prefix.
- dict_to_tsv(data_dict, filename)
Export data in dict format to a tsv file. One entry = one line
- Return type:
None
Parameters
- data_dict Dict[Any, List[Any]]:
any type of data in a dictionary format
- filename:
File name prefix. TSV will be appended and saved to outfolder with title prefix.
- get_outfolder()
Getter for name of folder where output is saved
- Return type:
str
Return
- outfolder: str
A subfolder in the workdir with the same name as the title
- list_to_file(data_list, filename, file_format='txt')
Export data in list format to a file. One entry = one line
- Return type:
None
Parameters
- data_list:
Any type of data in a list format
- filename:
Output file name (without extension)
- file_format: str
Format of the output file. Defaults to txt
- motif_to_meme(motifs, alphabet, file_prefix)
Save motif position probability matrices in meme format
- Return type:
None
Parameters
- motifs: Dict[str, np.ndarray]
the IDs and ppms of the simulated motifs
- alphabet: str
Characters in the order of column assignment (eg ACGT)
- file_prefix: str
Output file name prefix. Meme will be appended and saved to outfolder with title prefix.
- motived_and_plain_to_fasta(dagsim_data, no_motif_for_fasta, no_motif_prob)
Save fasta files with or without motived sequences.
- Return type:
None
Parameters
- dagsim_data: Dict[str, Any]
dictionary from the Dagsim output
- no_motif_for_fasta: List[str]
List of selected (not necessarily unique) background IDs and sequences without inserted motif
- no_motif_prob: List[np.ndarray]
List of corresponding sequence probabilties
- pandas_to_tsv(dataframe, filename)
Write pandas dataframe to file
- Return type:
None
Parameters
- dataframe: pd.DataFrame
Data to save
- filename: str
File name prefix. TSV will be appended and saved to outfolder with title prefix.
- save_dagsim_data(dagsim_data, nomotif_in_seq, nomotif_prob)
Save dagsim data and unmotived sequences to bed and fasta files
- Return type:
None
Parameters
- dagsim_data: Dict[str, Any]
dictionary from the Dagsim output
- nomotif_in_seq: List[str]
List of background ids and sequences without inserted motif
- nomotif_prob: List[np.ndarray]
List of corresponding sequence probabilties
- save_dictionary_with_numpy_to_npz(numpy_dict, filename)
Save dictionary with numpy arrays into npz format
- Return type:
None
Parameters
- numpy_dict: Dict[str, np.ndarray]
Dictionary with string keys and any dimensional numpy arrays as values
- filename: str
File name which will get the .npz extension.
- setup_dirs()
Create workfolder and outfolder if does not exist yet
- Return type:
None
Utility functions
- inmotifin.onehot_to_str(alphabet, motif_onehot)
Convert one-hot encoded motif into a string motif
- Return type:
str
Parameters
- alphabet: List[chr]
Allowed characters in the sequence (eg [A, C, G, T] or ‘ACGT’)
- motif_onehot: List[np.array]
One-hot encoded motif
Return
- motif: str
Motif in string format
- inmotifin.create_reverse_complement(alphabet, motif_instance)
Translate sequence to its reverse complement. Case sensitive
- Return type:
str
Parameters
- alphabet: Dict[chr, chr]
Pairs of characters and their complementary pairs e.g. {‘A’:’T’, ‘C’:’G’, ‘G’:’C’, ‘T’:’A’}
- motif_instance: str
Motif sequence
Return
- revcomp: str
Reverse complement of motif sequence
- inmotifin.define_complementary_map_motif_array(alphabet, alphabet_pairs)
Translate index of alphabet letter pair for column permutation
- Return type:
List[int]
Parameters
- alphabet: str
Alphabet in the order of motif numpy array columns
- alphabet_pairs: Dict[chr, chr]
Pairs of characters and their complementary pairs e.g. {‘A’:’T’, ‘C’:’G’, ‘G’:’C’, ‘T’:’A’}
Return
- complementary_idx: List[int]
Index of the partner of the letter
- inmotifin.create_reverse_complement_motif(motif, complementary_idx)
Translate index of alphabet letter pair
- Return type:
ndarray
Parameters
- motif: np.ndarray
PPM of a motif in shape (len, alphabet)
- complementary_idx: List[int]
Index of the partner of the letter
Return
- oriented_motif: np.ndarray
PPM of a reverse complemented motif in shape (len, alphabet)