Examples on how to work with the package from python
[1]:
import seqlogo
[1]:
import os
import glob
import pandas as pd
import numpy as np
import inmotifin
Running the main function: run_inmotifin()
[3]:
controller = inmotifin.Controller(
basic_params=inmotifin.BasicParams(
workdir=".",
title="run_inmotifin",
seed=47))
controller.run_inmotifin(
motif_params=inmotifin.MotifParams(
dirichlet_alpha=[0.1, 0.2, 0.3, 0.4],
number_of_motifs=5,
length_of_motifs_min=5,
length_of_motifs_max=6,
m_alphabet='ACGT',
m_alphabet_pairs={'A': 'T', 'C': 'G', 'G': 'C', 'T': 'A'}
),
background_params=inmotifin.BackgroundParams(
b_alphabet='ACGT',
b_alphabet_prior=[0.25, 0.25, 0.25, 0.25],
number_of_backgrounds=100,
length_of_backgrounds_min=50
),
group_params=inmotifin.GroupParams(
number_of_groups=1,
max_group_size=5,
group_size_binom_p=1
),
freq_params=inmotifin.FreqParams(
group_frequency_type="uniform",
motif_frequency_type="uniform",
group_group_type="uniform",
concentration_factor=1.
),
sampling_params=inmotifin.SamplingParams(
to_draw=False,
number_of_sequences=10,
percentage_no_motif=0.,
orientation_probability=0.5,
num_groups_per_sequence=1,
n_instances_per_sequence=1
),
positions_params=inmotifin.PositionParams(
position_type="central",
to_replace=True
)
)
Motifs created / read in
Backgrounds created / read in
Groups created / read in
Frequencies created / read in
2025-10-13 13:56:36.198571: Simulation started.
2025-10-13 13:56:36.199045: Simulating node "num_instances".
2025-10-13 13:56:36.199623: Simulating node "selected_groups".
2025-10-13 13:56:36.201724: Simulating node "backgrounds".
2025-10-13 13:56:36.203253: Simulating node "orientations".
2025-10-13 13:56:36.204152: Simulating node "selected_motifs".
2025-10-13 13:56:36.206493: Simulating node "instances".
2025-10-13 13:56:36.207798: Simulating node "positions".
2025-10-13 13:56:36.209460: Simulating node "motif_in_seq".
2025-10-13 13:56:36.211126: Simulating node "prob_motif_in_seq".
2025-10-13 13:56:36.224627: Simulation finished in 0.0261 seconds.
The probabilities are saved into a npz file
[4]:
np.load("run_inmotifin/run_inmotifin_probabilistic_final_sequences.npz")["0_run_inmotifin_seq_50"]
[4]:
array([[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[8.12316055e-07, 9.18805831e-03, 6.17911289e-01, 3.72899840e-01],
[2.42383660e-01, 5.11034517e-02, 1.51354558e-01, 5.55158330e-01],
[1.51177114e-20, 4.14834623e-01, 8.31469948e-02, 5.02018383e-01],
[1.23604868e-07, 4.75927467e-01, 2.03191682e-03, 5.22040493e-01],
[1.01009871e-12, 9.96524577e-01, 8.12731025e-06, 3.46729613e-03],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01],
[2.50000000e-01, 2.50000000e-01, 2.50000000e-01, 2.50000000e-01]])
Additional functionalities
[5]:
shared_reader=inmotifin.Reader()
Simulating motifs from scratch
[6]:
motif_writer = inmotifin.Writer(workdir=".", title="motif_sim")
rng=np.random.default_rng(391)
motifer = inmotifin.Motifer(
params=inmotifin.MotifParams(
dirichlet_alpha=[0.4,1,0.9,0.5],
number_of_motifs=5,
length_of_motifs_min=4,
length_of_motifs_max=8,
m_alphabet='ACGT',
m_alphabet_pairs={'A':'T','C':'G','G':'C','T':'A'}),
rng=rng,
reader=shared_reader,
writer=motif_writer)
[7]:
motifer.simulate_motifs()
motifs = motifer.get_pwms()
[8]:
motifs
[8]:
{'motif_sim_motif_0': array([[2.36249592e-01, 4.35283888e-01, 2.55462913e-01, 7.30036074e-02],
[2.72461841e-01, 4.49345991e-01, 2.68174909e-01, 1.00172591e-02],
[2.55062609e-02, 2.87485312e-01, 1.31186789e-01, 5.55821638e-01],
[1.92024167e-05, 6.09398867e-01, 3.46665574e-01, 4.39163562e-02]]),
'motif_sim_motif_1': array([[2.55318074e-02, 3.61328050e-02, 8.44714532e-01, 9.36208559e-02],
[8.92243821e-03, 4.94499198e-01, 4.96297606e-01, 2.80758192e-04],
[8.96516465e-03, 3.13749746e-01, 6.76873871e-01, 4.11218392e-04],
[3.00515697e-04, 9.42753584e-01, 3.47571177e-02, 2.21887826e-02]]),
'motif_sim_motif_2': array([[5.07066275e-02, 6.47016781e-01, 1.39802611e-01, 1.62473980e-01],
[3.45670050e-01, 2.30531323e-01, 4.23626136e-01, 1.72490043e-04],
[1.88227411e-01, 4.41151539e-01, 3.67392711e-01, 3.22833895e-03],
[1.49104503e-01, 3.94179471e-01, 4.45782876e-01, 1.09331502e-02]]),
'motif_sim_motif_3': array([[8.92697575e-03, 8.21430231e-01, 7.77393685e-02, 9.19034250e-02],
[4.07652524e-05, 3.72869252e-01, 3.99288257e-01, 2.27801726e-01],
[1.33615285e-01, 7.94650423e-02, 2.57937109e-01, 5.28982563e-01],
[5.46762104e-03, 5.33584687e-01, 3.82666062e-01, 7.82816295e-02],
[5.91298908e-03, 6.18222703e-02, 4.86627712e-01, 4.45637028e-01],
[1.81816713e-01, 1.75497072e-01, 6.39833446e-01, 2.85276863e-03],
[1.30527356e-01, 6.37975954e-02, 5.99585789e-01, 2.06089259e-01],
[2.88294043e-03, 7.53079965e-01, 1.47758218e-01, 9.62788764e-02]]),
'motif_sim_motif_4': array([[3.99530003e-02, 3.75628521e-02, 5.54581706e-01, 3.67902442e-01],
[2.24461182e-01, 6.39443929e-01, 1.36009753e-01, 8.51359567e-05],
[3.87618033e-01, 6.85954762e-02, 5.33612478e-01, 1.01740126e-02],
[9.05912173e-02, 1.75349027e-01, 3.08378086e-01, 4.25681670e-01],
[1.95323490e-01, 3.58472495e-01, 2.92022320e-01, 1.54181695e-01],
[1.01956221e-03, 7.16540811e-01, 2.52413014e-01, 3.00266132e-02]])}
[9]:
selected_motif_0 = 'motif_sim_motif_1'
selected_motif_1 = 'motif_sim_motif_3'
Plotting with seqlogo (note: not packaged with inMOTIFin)
[10]:
ppm0 = seqlogo.Ppm(motifs[selected_motif_0])
seqlogo.seqlogo(ppm0, ic_scale = True, format = 'png', size = 'small')
[10]:
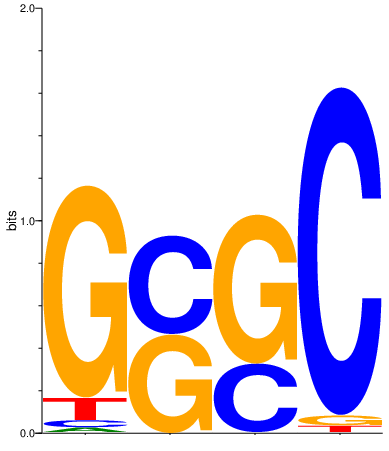
[11]:
ppm1 = seqlogo.Ppm(motifs[selected_motif_1])
seqlogo.seqlogo(ppm1, ic_scale = True, format = 'png')
[11]:

Saving motifs to meme file
[12]:
motif_writer.motif_to_meme(
motifs=motifs,
alphabet='ACGT',
file_prefix="simulated_motifs")
Creating multimers from motifs
[13]:
multimerer = inmotifin.Multimerer(
params=inmotifin.MultimerParams(
motif_files=None,
multimerisation_rule_path=None),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="multimer_sim"),
rng=rng)
[14]:
multimerer.set_motifs(motifer.get_motifs())
[ ]:
multimer = multimerer.create_a_multimer(
motifs=[motifs[selected_motif_0], motifs[selected_motif_1]],
distances=[2])
[16]:
ppmd = seqlogo.Ppm(multimer)
seqlogo.seqlogo(ppmd, ic_scale = True, format = 'png')
[16]:
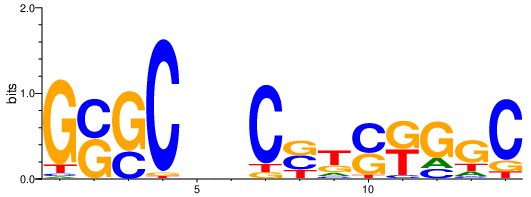
Multimers can have negative distance, in that case the average is taken
[17]:
multimer_neg = multimerer.create_a_multimer(
motifs=[motifs[selected_motif_0], motifs[selected_motif_1]],
distances=[-1])
[18]:
ppmd_n = seqlogo.Ppm(multimer_neg)
seqlogo.seqlogo(ppmd_n, ic_scale = True, format = 'png')
[18]:

The weight of the individual components can be set. In this example, the middle motif gets the most weight when averaging overlapping positions.
[19]:
multimer_weighted_neg = multimerer.create_a_multimer(
motifs=[motifs[selected_motif_1], motifs[selected_motif_0], motifs[selected_motif_0]],
distances=[-4, -1],
weights=[1, 100, 1])
[20]:
ppmd_n = seqlogo.Ppm(multimer_weighted_neg)
seqlogo.seqlogo(ppmd_n, ic_scale = True, format = 'png')
[20]:

One may add noise to a motif by setting the distance is equal to the length of the motif and the “multimer pair” to a non-informative motif.
[21]:
motifs['motif_sim_motif_3']
[21]:
array([[8.92697575e-03, 8.21430231e-01, 7.77393685e-02, 9.19034250e-02],
[4.07652524e-05, 3.72869252e-01, 3.99288257e-01, 2.27801726e-01],
[1.33615285e-01, 7.94650423e-02, 2.57937109e-01, 5.28982563e-01],
[5.46762104e-03, 5.33584687e-01, 3.82666062e-01, 7.82816295e-02],
[5.91298908e-03, 6.18222703e-02, 4.86627712e-01, 4.45637028e-01],
[1.81816713e-01, 1.75497072e-01, 6.39833446e-01, 2.85276863e-03],
[1.30527356e-01, 6.37975954e-02, 5.99585789e-01, 2.06089259e-01],
[2.88294043e-03, 7.53079965e-01, 1.47758218e-01, 9.62788764e-02]])
[22]:
motif_len = motifs['motif_sim_motif_3'].shape[0]
[23]:
noise = np.tile(np.array([0.25]*4), (motif_len, 1))
noise
[23]:
array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]])
[24]:
updated_motifs = motifer.get_motifs()
updated_motifs.motifs["motif_sim_motif_noised_3"] = noise
updated_motifs.motif_ids.append("motif_sim_motif_noised_3")
[25]:
updated_motifs
[25]:
Motifs(motifs={'motif_sim_motif_0': array([[2.36249592e-01, 4.35283888e-01, 2.55462913e-01, 7.30036074e-02],
[2.72461841e-01, 4.49345991e-01, 2.68174909e-01, 1.00172591e-02],
[2.55062609e-02, 2.87485312e-01, 1.31186789e-01, 5.55821638e-01],
[1.92024167e-05, 6.09398867e-01, 3.46665574e-01, 4.39163562e-02]]), 'motif_sim_motif_1': array([[2.55318074e-02, 3.61328050e-02, 8.44714532e-01, 9.36208559e-02],
[8.92243821e-03, 4.94499198e-01, 4.96297606e-01, 2.80758192e-04],
[8.96516465e-03, 3.13749746e-01, 6.76873871e-01, 4.11218392e-04],
[3.00515697e-04, 9.42753584e-01, 3.47571177e-02, 2.21887826e-02]]), 'motif_sim_motif_2': array([[5.07066275e-02, 6.47016781e-01, 1.39802611e-01, 1.62473980e-01],
[3.45670050e-01, 2.30531323e-01, 4.23626136e-01, 1.72490043e-04],
[1.88227411e-01, 4.41151539e-01, 3.67392711e-01, 3.22833895e-03],
[1.49104503e-01, 3.94179471e-01, 4.45782876e-01, 1.09331502e-02]]), 'motif_sim_motif_3': array([[8.92697575e-03, 8.21430231e-01, 7.77393685e-02, 9.19034250e-02],
[4.07652524e-05, 3.72869252e-01, 3.99288257e-01, 2.27801726e-01],
[1.33615285e-01, 7.94650423e-02, 2.57937109e-01, 5.28982563e-01],
[5.46762104e-03, 5.33584687e-01, 3.82666062e-01, 7.82816295e-02],
[5.91298908e-03, 6.18222703e-02, 4.86627712e-01, 4.45637028e-01],
[1.81816713e-01, 1.75497072e-01, 6.39833446e-01, 2.85276863e-03],
[1.30527356e-01, 6.37975954e-02, 5.99585789e-01, 2.06089259e-01],
[2.88294043e-03, 7.53079965e-01, 1.47758218e-01, 9.62788764e-02]]), 'motif_sim_motif_4': array([[3.99530003e-02, 3.75628521e-02, 5.54581706e-01, 3.67902442e-01],
[2.24461182e-01, 6.39443929e-01, 1.36009753e-01, 8.51359567e-05],
[3.87618033e-01, 6.85954762e-02, 5.33612478e-01, 1.01740126e-02],
[9.05912173e-02, 1.75349027e-01, 3.08378086e-01, 4.25681670e-01],
[1.95323490e-01, 3.58472495e-01, 2.92022320e-01, 1.54181695e-01],
[1.01956221e-03, 7.16540811e-01, 2.52413014e-01, 3.00266132e-02]]), 'motif_sim_motif_noised_3': array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]])}, alphabet='ACGT', alphabet_revcomp_pairs={'A': 'T', 'C': 'G', 'G': 'C', 'T': 'A'}, motif_ids=['motif_sim_motif_0', 'motif_sim_motif_1', 'motif_sim_motif_2', 'motif_sim_motif_3', 'motif_sim_motif_4', 'motif_sim_motif_noised_3'])
[26]:
# Adding one more motif to the set of motifs in multimerer
multimerer.set_motifs(updated_motifs)
[27]:
multimer_parts_noised = (["motif_sim_motif_3", "motif_sim_motif_noised_3"], [-motif_len])
multimer_noised = multimerer.create_a_multimer(
motifs=[motifs["motif_sim_motif_3"], motifs["motif_sim_motif_noised_3"]],
distances=[-motif_len])
[28]:
multimer_noised
[28]:
array([[0.12946349, 0.53571512, 0.16386968, 0.17095171],
[0.12502038, 0.31143463, 0.32464413, 0.23890086],
[0.19180764, 0.16473252, 0.25396855, 0.38949128],
[0.12773381, 0.39179234, 0.31633303, 0.16414081],
[0.12795649, 0.15591114, 0.36831386, 0.34781851],
[0.21590836, 0.21274854, 0.44491672, 0.12642638],
[0.19026368, 0.1568988 , 0.42479289, 0.22804463],
[0.12644147, 0.50153998, 0.19887911, 0.17313944]])
[29]:
ppmd_original = seqlogo.Ppm(updated_motifs.motifs["motif_sim_motif_3"])
seqlogo.seqlogo(ppmd_original, ic_scale = True, format = 'png')
[29]:

[30]:
ppmd_noisy = seqlogo.Ppm(multimer_noised)
seqlogo.seqlogo(ppmd_noisy, ic_scale = True, format = 'png')
[30]:
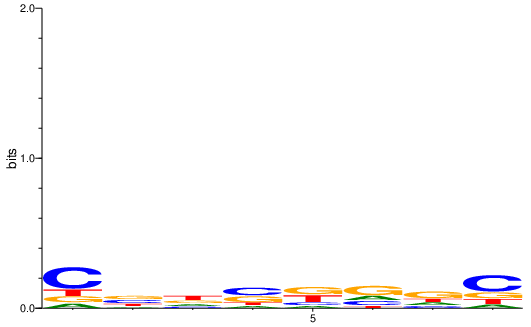
An alterantive way to noise a motif is to add a small value to all elements of the matrix, then re-normalize
[31]:
epsilon = 1e-1
noisy = motifs['motif_sim_motif_3'] + epsilon
noisy = noisy / noisy.sum(axis=1, keepdims=True)
motifs["noisy"] = noisy
noisy
[31]:
array([[0.07780498, 0.65816445, 0.12695669, 0.13707388],
[0.07145769, 0.33776375, 0.35663447, 0.23414409],
[0.16686806, 0.12818932, 0.25566936, 0.44927326],
[0.07533402, 0.45256049, 0.34476147, 0.12734402],
[0.07565214, 0.11558734, 0.41901979, 0.38974073],
[0.20129765, 0.19678362, 0.52845246, 0.07346626],
[0.1646624 , 0.11699828, 0.49970414, 0.21863519],
[0.07348781, 0.60934283, 0.17697016, 0.1401992 ]])
Reading motifs in from meme file
[32]:
motifs_m, alphabet_m = shared_reader.read_motif(
mfile = "motif_read_in/jaspar_core_three_motifs.meme")
[33]:
motifs_m
[33]:
{'MA0001.1': array([[0. , 0.969072 , 0.010309 , 0.020619 ],
[0.030928 , 0.773196 , 0. , 0.195876 ],
[0.814433 , 0.041237 , 0.030928 , 0.113402 ],
[0.412371 , 0.030928 , 0.041237 , 0.515464 ],
[0.68041268, 0.01030901, 0.01030901, 0.2989693 ],
[0.494845 , 0.020619 , 0. , 0.484536 ],
[0.67010367, 0.05154605, 0.05154605, 0.22680423],
[0.11340189, 0.02061898, 0.03092797, 0.83505116],
[0.670103 , 0.030928 , 0.28866 , 0.010309 ],
[0. , 0.030928 , 0.907216 , 0.061856 ]]),
'MA0003.1': array([[0. , 0. , 1. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0.11891888, 0.38378362, 0.24864875, 0.24864875],
[0.102703 , 0.308108 , 0.32973 , 0.259459 ],
[0.297297 , 0.237838 , 0.362162 , 0.102703 ],
[0.28648629, 0.16216216, 0.49189249, 0.05945906],
[0.102703 , 0.086486 , 0.740541 , 0.07027 ],
[0.04864895, 0.42162158, 0.42702657, 0.1027029 ]]),
'MA0002.2': array([[0.1435, 0.248 , 0.348 , 0.2605],
[0.117 , 0.2425, 0.2335, 0.407 ],
[0.0615, 0.536 , 0.0745, 0.328 ],
[0.0285, 0. , 0.0035, 0.968 ],
[0. , 0.0375, 0.936 , 0.0265],
[0.0435, 0.0635, 0.035 , 0.858 ],
[0. , 0. , 0.9935, 0.0065],
[0.0085, 0.021 , 0.924 , 0.0465],
[0.005 , 0.2 , 0.1255, 0.6695],
[0.0655, 0.2315, 0.0405, 0.6625],
[0.25 , 0.079 , 0.1445, 0.5265]])}
[34]:
alphabet_m
[34]:
'ACGT'
Reading motifs in from jaspar file
The values are normalized to 1, so the PFM is converted to PWM
[35]:
motifs_j, alphabet_j = shared_reader.read_motif(
mfile = "motif_read_in/jaspar_core_three_motifs.jaspar")
[36]:
motifs_j
[36]:
{'MA0001.1': array([[0. , 0.96907216, 0.01030928, 0.02061856],
[0.03092784, 0.77319588, 0. , 0.19587629],
[0.81443299, 0.04123711, 0.03092784, 0.11340206],
[0.41237113, 0.03092784, 0.04123711, 0.51546392],
[0.68041237, 0.01030928, 0.01030928, 0.29896907],
[0.49484536, 0.02061856, 0. , 0.48453608],
[0.67010309, 0.05154639, 0.05154639, 0.22680412],
[0.11340206, 0.02061856, 0.03092784, 0.83505155],
[0.67010309, 0.03092784, 0.28865979, 0.01030928],
[0. , 0.03092784, 0.90721649, 0.06185567]]),
'MA0003.1': array([[0. , 0. , 1. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0.11891892, 0.38378378, 0.24864865, 0.24864865],
[0.1027027 , 0.30810811, 0.32972973, 0.25945946],
[0.2972973 , 0.23783784, 0.36216216, 0.1027027 ],
[0.28648649, 0.16216216, 0.49189189, 0.05945946],
[0.1027027 , 0.08648649, 0.74054054, 0.07027027],
[0.04864865, 0.42162162, 0.42702703, 0.1027027 ]]),
'MA0002.2': array([[0.1435, 0.248 , 0.348 , 0.2605],
[0.117 , 0.2425, 0.2335, 0.407 ],
[0.0615, 0.536 , 0.0745, 0.328 ],
[0.0285, 0. , 0.0035, 0.968 ],
[0. , 0.0375, 0.936 , 0.0265],
[0.0435, 0.0635, 0.035 , 0.858 ],
[0. , 0. , 0.9935, 0.0065],
[0.0085, 0.021 , 0.924 , 0.0465],
[0.005 , 0.2 , 0.1255, 0.6695],
[0.0655, 0.2315, 0.0405, 0.6625],
[0.25 , 0.079 , 0.1445, 0.5265]])}
[37]:
alphabet_j
[37]:
'ACGT'
Reading motifs in from JASPAR database
The values are normalized to 1, so the PFM is converted to PWM
[38]:
motifs_pj, alphabet_pj = shared_reader.read_motif(
mfile = "motif_read_in/jaspar_motifs.csv",
jaspar_db_version='JASPAR2024')
[39]:
motifs_pj
[39]:
{'MA0001.1': array([[0. , 0.96907216, 0.01030928, 0.02061856],
[0.03092784, 0.77319588, 0. , 0.19587629],
[0.81443299, 0.04123711, 0.03092784, 0.11340206],
[0.41237113, 0.03092784, 0.04123711, 0.51546392],
[0.68041237, 0.01030928, 0.01030928, 0.29896907],
[0.49484536, 0.02061856, 0. , 0.48453608],
[0.67010309, 0.05154639, 0.05154639, 0.22680412],
[0.11340206, 0.02061856, 0.03092784, 0.83505155],
[0.67010309, 0.03092784, 0.28865979, 0.01030928],
[0. , 0.03092784, 0.90721649, 0.06185567]]),
'MA0003.1': array([[0. , 0. , 1. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0.11891892, 0.38378378, 0.24864865, 0.24864865],
[0.1027027 , 0.30810811, 0.32972973, 0.25945946],
[0.2972973 , 0.23783784, 0.36216216, 0.1027027 ],
[0.28648649, 0.16216216, 0.49189189, 0.05945946],
[0.1027027 , 0.08648649, 0.74054054, 0.07027027],
[0.04864865, 0.42162162, 0.42702703, 0.1027027 ]]),
'MA0002.2': array([[0.1435, 0.248 , 0.348 , 0.2605],
[0.117 , 0.2425, 0.2335, 0.407 ],
[0.0615, 0.536 , 0.0745, 0.328 ],
[0.0285, 0. , 0.0035, 0.968 ],
[0. , 0.0375, 0.936 , 0.0265],
[0.0435, 0.0635, 0.035 , 0.858 ],
[0. , 0. , 0.9935, 0.0065],
[0.0085, 0.021 , 0.924 , 0.0465],
[0.005 , 0.2 , 0.1255, 0.6695],
[0.0655, 0.2315, 0.0405, 0.6625],
[0.25 , 0.079 , 0.1445, 0.5265]])}
[40]:
alphabet_pj
[40]:
'ACGT'
Tip: to create specific sequences, use one-hot encoded numpy array as motif.
Creating random GC-rich backgrounds
[41]:
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGT",
b_alphabet_prior=[0.25, 0.25, 0.25, 0.25],
number_of_backgrounds=3,
length_of_backgrounds_min=10,
length_of_backgrounds_max=15),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="background_sim"),
rng=rng)
[42]:
backgrounds = backgrounder.simulate_iid_backgrounds()
[43]:
backgrounds
[43]:
({'background_sim_seq_0': 'AAATAGCATCGTA',
'background_sim_seq_1': 'TCGAGGAGACACC',
'background_sim_seq_2': 'CTAATCTGGT'},
{'background_sim_seq_0': array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]]),
'background_sim_seq_1': array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]]),
'background_sim_seq_2': array([[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25],
[0.25, 0.25, 0.25, 0.25]])})
[44]:
backgrounder.writer.dict_to_fasta(
seq_dict=backgrounds[0],
filename="backgrounds")
Reading in sequences form a fasta file
An additional index is added to the end of the sequence, in case there would be two identically named sequences. Note: if any sequence is duplicated in the original file, they would be present twice with unique IDs (as demonstrated with sequence SRR30315250.1).
[45]:
SRR30315250_sequences = shared_reader.read_fasta(
fasta_files=["background_read_in/SRR30315250_subset.fasta"])
SRR30315250_sequences
[45]:
{'SRR30315250.1_0': 'CNAGGATTCACGCAATTTGTGTGGACCAGCAGATGGTCTTGGGGCGTAACAACCGGACAACTTGTCCAATAACCAATGGTGTGGAGCTGCTAATCTCTTTAGATGCTTCTTTGGTCCTCTAGCCATCTTTCCTCAATAGTGGTGTATCTA',
'SRR30315250.1_1': 'CNAGGATTCACGCAATTTGTGTGGACCAGCAGATGGTCTTGGGGCGTAACAACCGGACAACTTGTCCAATAACCAATGGTGTGGAGCTGCTAATCTCTTTAGATGCTTCTTTGGTCCTCTAGCCATCTTTCCTCAATAGTGGTGTATCTA',
'SRR30315250.2_0': 'CNATCCACTTGGATTTGTCTTCATCTCTCATTTCCAAAGCTTCGTGGACACCGGTGGAGGCACCAGATGGAACAATGGATCTGAAAACACCCTTTTCGGTGGTTAATTCGACTTCGACGGTTGGGTTACCACGGGAGTCGTAGACGGATC',
'SRR30315250.3_0': 'GTCCCATCCTTTAATTACTTCGCCTTGGCCCAACTTAAAAACAAAAGGCTTACCCTTTGTATTCTTGTCAAAAACTTTCCCGTTCTTCAACTTACCAACATATCTCATTCCAACTCTGGTACCCTTTTTGGCATGTGGGCCTTTTCCTGT',
'SRR30315250.4_0': 'CCATCTTTTCTGCTGGGATGAAAAGCTTCCAATTCCTCTTATAGATCTTGTGTCCGATGTACATAACCATAACAAGTGGGAAGGATAGATAAGCTTCGAAGAAACCTTCCGCACTTGGAGAATCTCCCACGGGGAATAGAGCAACGTAGA',
'SRR30315250.5_0': 'CTTTGATTCCCTTCTCTAAAGCAGTAGGGTTAGCTCCAATGATCTTGCCGATGAGTTGGCCATCCTTGCCAAGAACAAAGGTGGGCATAGCCGTCACTTCACACTCTTTGGCAATATCTGGTGATTCGTCCACGTCGCACTTGACAAATC',
'SRR30315250.6_0': 'TGAACCAATTTATTTTTCGTTACATAAAAATGCTTATAAAACTTTAACTAATAATTAGAGATTAAATCGCTTATTGCTTAGCGTTGGTAGCAGCAGTCAACTTAGCTTGTTCAACCAAGTTTTGTGGAGCATCGAAGACTGGCAACATGA',
'SRR30315250.7_0': 'ATCAATTGCCCGATGTAAACGCGGCCATCTTGAGTGAGAACCCTCAGCTTATAATCAATAAGGTTGGCTAGTCGGCTGCTATGTGCCACCTGTATTTTGCTCATTAGTTATTTACTTAGATCGGAAGAGCACACGTCTGAACTCCAGTCA',
'SRR30315250.8_0': 'CCTATGTCTTGGAACATGTTGCAAAGCGGTTGTGAAGCTCAACAAAAGGAACTCCATTTCCTCTTTTTCATTTCCTTTGCTATTCTTGATCAAGGCAGGGACAACAGTTAGTATCGTACGCTCAACAACTTTAGTTGTGAATTCAGATCG',
'SRR30315250.9_0': 'CTGGCGAAGAAGTCCAAAGCTTCTCTGGTGTCAGCTCTGTTACCGACGTAAGAACCAACAATAGAGATGGACTTGACGACTTGGTTGAAGACATCAGAACAACACTTGGCACCAGCTGGCATACCGACCAAAACGGTGGTACCGTTAGCT',
'SRR30315250.10_0': 'TTTTCCATCTTTTCGTAAATTTCTGGCAAGGTAGACAAGCCGACAACCTTGATTGGAGACTTGACCAAACCTCTGGCGAAGAAGTCCAAAGCTTCTCTGGTGTCAGCTCTGTTACCGACGTAAGAACCAACAATAGAGAGATCGGAAGAG',
'SRR30315250.11_0': 'GTTTCTAACGACAGAAACTCTTGGAATGGGTGCGAATGGGAACAATAACTCTTCTCTCAAACTATTTTCATCGGCATTTTCATTAACTTGCATAATCTTCAAAGTACACATATCATCACGTTCTCTAGAGTCTCTGTAAGCATCGGATGA',
'SRR30315250.12_0': 'GTCCATATCATCTCATCATTTTGTAGTTTTTGCAGTCTGTACTTGTATTCTTCAATCAACTTTTCATTCTTGTCAGTGCTATTAGCTACTACGTTTTTTGGCGTTGCCAAAGACTTAGACGTCAACAGGACCCTCGATTTATTGTTAGCA',
'SRR30315250.13_0': 'CTGGAGCATTGTCGTAACCCCCAGATTGTGGAGAGGGAAAGGTACCTTCAGTGATAATCAAGGTTCCTGGTCTTTGAGCACGTTGAGCGTAGTATTCAACGGCCCAGTCTCTGTTTGGAATATTACCTGGATGTTGGGCTCTCATTCTAG',
'SRR30315250.14_0': 'CTTTGGACCAGTTCTGCTCTTAGCTGGGTCTCTCATAATCTTAACCTTGATACCCAAAACACCTTGTCTCATCAAGACGTGTCTAGTAGCAGTGTCAATGAAGTCGTTGACTGGTTGACCAGAGTGAATCAAGAAACCGTCAGCAAATTT',
'SRR30315250.15_0': 'ACCAACCATTAAAGCTTCAGCTTGAGCAAAGAAGTTTGAAGCCAACATCTTTTGATGTAATTTGTTCTCAATTGGGTTATGAGATTGAGCAGCTAAGATGAAATCAGATGGAATCAACTTGGTACCTTGGTGAACCAATTGGAAGAAAGA'}
Reading in sequences form a fasta file and assign i.i.d. probabilities per position
[46]:
rng=np.random.default_rng(391)
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGT",
background_files=["background_read_in/SRR30315250_subset.fasta"],
background_type="fasta_iid"),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="background_fasta_iid"),
rng=rng)
[47]:
backgrounder.create_backgrounds()
backgrounder.get_backgrounds().background_ids[:10]
[47]:
['SRR30315250.10_0',
'SRR30315250.11_0',
'SRR30315250.12_0',
'SRR30315250.13_0',
'SRR30315250.14_0',
'SRR30315250.15_0',
'SRR30315250.1_0',
'SRR30315250.1_1',
'SRR30315250.2_0',
'SRR30315250.3_0']
Reading in sequences form a fasta file and shuffle by nucleotide keeping only the shuffled sequences
The probabilities are assigned iid
[48]:
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGT",
background_files=["background_read_in/SRR30315250_subset.fasta"],
background_type="random_nucl_shuffled_only",
number_of_shuffle=2),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="background_shuffled_only"),
rng=rng)
backgrounder.create_backgrounds()
backgrounder.get_backgrounds().background_ids[:10]
[48]:
['SRR30315250.10_0_shuffled1',
'SRR30315250.10_0_shuffled2',
'SRR30315250.11_0_shuffled1',
'SRR30315250.11_0_shuffled2',
'SRR30315250.12_0_shuffled1',
'SRR30315250.12_0_shuffled2',
'SRR30315250.13_0_shuffled1',
'SRR30315250.13_0_shuffled2',
'SRR30315250.14_0_shuffled1',
'SRR30315250.14_0_shuffled2']
Reading in sequences form a fasta file and shuffle by nucleotide keeping both the original and the shuffled sequences
[49]:
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGT",
background_files=["background_read_in/SRR30315250_subset.fasta"],
background_type="random_nucl_shuffled_addon",
number_of_shuffle=2),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="background_shuffled_only"),
rng=rng)
backgrounder.create_backgrounds()
backgrounder.get_backgrounds().background_ids[:10]
[49]:
['SRR30315250.10_0',
'SRR30315250.10_0_shuffled1',
'SRR30315250.10_0_shuffled2',
'SRR30315250.11_0',
'SRR30315250.11_0_shuffled1',
'SRR30315250.11_0_shuffled2',
'SRR30315250.12_0',
'SRR30315250.12_0_shuffled1',
'SRR30315250.12_0_shuffled2',
'SRR30315250.13_0']
Reading in sequences form a fasta file, fit HMM of order 1, then sample new sequences
[51]:
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGTN",
background_files=["background_read_in/SRR30315250_subset.fasta"],
background_type="markov_sim",
markov_order=1,
length_of_backgrounds_min=10,
length_of_backgrounds_max=20,
number_of_backgrounds=20),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="markov_sim"),
rng=rng)
backgrounder.create_backgrounds()
hhmbckgsim = backgrounder.get_backgrounds()
hhmbckgsim.backgrounds
[51]:
{'markov_sim_seq_0': 'TTGGCTTTTTGTCG',
'markov_sim_seq_1': 'ATAGTGAATCCGAA',
'markov_sim_seq_2': 'CAACTGTACTGCACTC',
'markov_sim_seq_3': 'TGAATCAACT',
'markov_sim_seq_4': 'GCAATCAAAA',
'markov_sim_seq_5': 'TCCAACCAGCAACAACGAAG',
'markov_sim_seq_6': 'TTCTGTCNACTCTCAT',
'markov_sim_seq_7': 'GCAATGCAGCGTTTTATTC',
'markov_sim_seq_8': 'NTTATAATAGAGCA',
'markov_sim_seq_9': 'GAACAGTCCTTCGAACCTC',
'markov_sim_seq_10': 'CCGGCTCAATCTCTTCAA',
'markov_sim_seq_11': 'GGAGAACGTCGATGA',
'markov_sim_seq_12': 'GTTCCAGGAGCAAGTATCTG',
'markov_sim_seq_13': 'AATTCGAGATGAAGCCA',
'markov_sim_seq_14': 'TCTAATTTAGTTCTCTG',
'markov_sim_seq_15': 'TTTCTGTGCC',
'markov_sim_seq_16': 'TAGTGAATCTGTTTTA',
'markov_sim_seq_17': 'TGTTCAAAGCATTCATCTA',
'markov_sim_seq_18': 'CTGAGGGAATCGCAA',
'markov_sim_seq_19': 'ATCAGTGAATTGTTTCATC'}
Sampling instances from motifs
[52]:
instancer = inmotifin.MotifInstancer(
motifs=motifer.get_motifs(),
rng=rng
)
instances = instancer.sample_instances(
motif_idx_list=[selected_motif_0, selected_motif_1],
orientations=[0, 1] # where 1 means forward, 0 means reverse complement
)
[53]:
instances
[53]:
['GCGC', 'CCTCTCTC']
Inserting instances into backgrounds at specific locations, different location for each motif in each background
[54]:
controller = inmotifin.Controller(
basic_params=inmotifin.BasicParams(
workdir=".",
title="controller_insertion",
seed=47))
backgrounds = {
"b0": "AAAAAAAAAAACAAAACAAAAAAA",
"b1": "CCCCCCCCCGCCCCCCCGCCCCCCC",
"b2": "TTTTTATTTTTTTTTTTTTTTTATT"}
b_alphabets = {
"b0": 'ACGT',
"b1": "ACGT",
"b2": "ACGT"}
sequence_probs = {
"b0": np.tile(
np.array([.9, .1, 0., 0.]), (len(backgrounds["b0"]), 1)),
"b1": np.tile(
np.array([0., .9, .1, 0.]), (len(backgrounds["b1"]), 1)),
"b2": np.tile(
np.array([.1, 0., 0., .9]), (len(backgrounds["b2"]), 1))}
motifs = inmotifin.Motifs(
motifs={
"m0": np.array([
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 0, 1, 0]]),
"m1": np.array([
[1, 0, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0],
[0, 1, 0, 0]]),
"m2": np.array([
[0, 0, 1, 0],
[1, 0, 0, 0]])},
alphabet="ACGT",
alphabet_revcomp_pairs={
'A': 'T', 'C': 'G', 'T': 'A', 'G': 'C'},
)
background_ids = ["b0", "b0", "b1", "b0", "b2"]
motif_ids = [
["m0"],
["m1"],
["m0", "m2"],
["m1", "m1", "m0"],
["m2"]]
positions = [
[(1, 4)],
[(8, 12)],
[(1, 4), (9, 11)],
[(2, 6), (8, 12), (13, 16)],
[(5, 7)]]
orientations = [[1], [0], [1, 1], [0, 0, 1], [1]]
motif_in_sequences, probabilistic_motif_in_sequences = controller.create_motif_in_seq(
background_ids=background_ids,
background_dict=backgrounds,
b_alphabets=b_alphabets,
sequence_probs=sequence_probs,
positions=positions,
motif_ids=motif_ids,
motifs=motifs,
orientations=orientations,
to_replace=True)
[55]:
# the name of the sequences are: background id, motif id, position, orientation
motif_in_sequences
[55]:
{'b0_m0_1:4_1': 'AAGGAAAAAAACAAAACAAAAAAA',
'b0_m1_8:12_0': 'AAAAAAAAGTTTAAAACAAAAAAA',
'b1_m0_m2_1:4_9:11_1_1': 'CAGGCCCCCGACCCCCCGCCCCCCC',
'b0_m1_m1_m0_2:6_8:12_13:16_0_0_1': 'AAGTTTAAGTTTAAGGCAAAAAAA',
'b2_m2_5:7_1': 'TTTTTGATTTTTTTTTTTTTTTATT'}
[56]:
# here the sequences are represented by letter probability in each position
probabilistic_motif_in_sequences["b1_m0_m2_1:4_9:11_1_1"]
[56]:
array([[0. , 0.9, 0.1, 0. ],
[1. , 0. , 0. , 0. ],
[0. , 0. , 1. , 0. ],
[0. , 0. , 1. , 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0. , 1. , 0. ],
[1. , 0. , 0. , 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ],
[0. , 0.9, 0.1, 0. ]])
[57]:
controller.writer.dict_to_fasta(
seq_dict=motif_in_sequences,
filename="motif_in_seq")
[58]:
controller.writer.save_dictionary_with_numpy_to_npz(
numpy_dict=probabilistic_motif_in_sequences,
filename="probabilistic_motif_in_seq")
Sampling motifs from groups to mimic soft-syntax (billboard model)
First, create initial group sampling probabilities. Code for automatic assignment is shown after the manual examples.
[59]:
rng = np.random.default_rng(123)
group_freq={
"t1": 0.8,
"t2": 0.1,
"t3": 0.1}
group_freq
[59]:
{'t1': 0.8, 't2': 0.1, 't3': 0.1}
Then, assign motifs to groups with specific probabilities. Note, the sum of motif probabilities per group == 1.
[60]:
motif_freq_per_group_df = pd.DataFrame({
"t1": {"m1": 0.5, "m2": 0.5},
"t2": {"m1": 0.9, "m3": 0.1},
"t3": {"m2": 0.25, "m3": 0.25, "m4": 0.5}})
motif_freq_per_group_df.fillna(value=0, inplace=True)
motif_freq_per_group_df
[60]:
| t1 | t2 | t3 | |
|---|---|---|---|
| m1 | 0.5 | 0.9 | 0.00 |
| m2 | 0.5 | 0.0 | 0.25 |
| m3 | 0.0 | 0.1 | 0.25 |
| m4 | 0.0 | 0.0 | 0.50 |
Finally, assign group transition probabilties.
[61]:
group_group_transition_prob=pd.DataFrame(
np.array([
[0.6, 0.2, 0.2],
[0.1, 0.6, 0.3],
[0.2, 0.2, 0.6]]),
index=["t1", "t2", "t3"],
columns=["t1", "t2", "t3"])
group_group_transition_prob
[61]:
| t1 | t2 | t3 | |
|---|---|---|---|
| t1 | 0.6 | 0.2 | 0.2 |
| t2 | 0.1 | 0.6 | 0.3 |
| t3 | 0.2 | 0.2 | 0.6 |
[62]:
frequencies = inmotifin.Frequencies(
group_freq=group_freq,
motif_freq_per_group=motif_freq_per_group_df,
group_group_transition_prob=group_group_transition_prob)
Alternatively, helper functions can be used
[63]:
grouper = inmotifin.Grouper(
params=inmotifin.GroupParams(
number_of_groups=3,
max_group_size=3,
group_size_binom_p=0.8),
motif_ids=["m1", "m2", "m3", "m4"],
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="group_sim"),
rng=rng)
grouper.create_groups()
frequencer = inmotifin.Frequencer(
params=inmotifin.FreqParams(
group_frequency_type="random",
group_frequency_range=10,
motif_frequency_type="random",
motif_frequency_range=20,
group_group_type="random",
concentration_factor=0.6
),
groups=grouper.get_groups(),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="group_sim"),
rng=rng)
frequencer.assign_frequencies()
[64]:
frequencer.frequencies
[64]:
Frequencies(num_groups=3, group_freq={'group_sim_group_0': np.float64(0.45454545454545453), 'group_sim_group_1': np.float64(0.2727272727272727), 'group_sim_group_2': np.float64(0.2727272727272727)}, motif_freq_per_group= group_sim_group_0 group_sim_group_1 group_sim_group_2
m1 0.666667 0.162162 0.485714
m4 0.333333 0.000000 0.028571
m2 0.000000 0.405405 0.000000
m3 0.000000 0.432432 0.485714, group_group_transition_prob= group_sim_group_0 group_sim_group_1 group_sim_group_2
group_sim_group_0 0.600000 0.329697 0.070303
group_sim_group_1 0.085505 0.600000 0.314495
group_sim_group_2 0.296587 0.103413 0.600000)
After setting up, the groups can be sampled.
[65]:
num_groups_per_seq = 8
test_freq = inmotifin.FrequencySampler(
frequencies=frequencies,
num_groups_per_seq=num_groups_per_seq,
rng=rng)
selected_groups = test_freq.select_groups()
selected_groups
[65]:
['t1', 't3', 't2', 't3', 't3', 't2', 't2', 't2']
From groups, motifs are sampled following the motif per group probabilities.
[66]:
motif_freq_per_group_df
[66]:
| t1 | t2 | t3 | |
|---|---|---|---|
| m1 | 0.5 | 0.9 | 0.00 |
| m2 | 0.5 | 0.0 | 0.25 |
| m3 | 0.0 | 0.1 | 0.25 |
| m4 | 0.0 | 0.0 | 0.50 |
[67]:
selected_motifs = test_freq.select_motifs_from_groups(
group_ids=selected_groups,
num_instances_per_seq=12,
w_replacement=True)
selected_motifs
[67]:
['m2', 'm2', 'm1', 'm3', 'm4', 'm3', 'm1', 'm3', 'm2', 'm1', 'm3', 'm1']
Note, these functions assume sampling groups and motifs per sequence. Therefore, they only sample once.
Insert motifs to specific locations given the group they were sampled from
First, sets of groups are selected. Then motifs per group are sampled. Next, group sets per sequence are sampled. Finally, for each set of group, a location is assigned in each sequence.
[68]:
grouper = inmotifin.Grouper(
params=inmotifin.GroupParams(
number_of_groups=3,
max_group_size=3,
group_size_binom_p=0.8),
motif_ids=["m1", "m2", "m3", "m4"],
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="group_loc_sim"),
rng=rng)
grouper.create_groups()
frequencer = inmotifin.Frequencer(
params=inmotifin.FreqParams(
group_frequency_type="uniform",
motif_frequency_type="random",
motif_frequency_range=20,
group_group_type="uniform",
concentration_factor=0.8
),
groups=grouper.get_groups(),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="group_loc_sim"),
rng=rng)
frequencer.assign_frequencies()
[69]:
# create mock motif instances
motif_instances = {
"m1": "AAAA",
"m2": "CCC",
"m3": "TTTT",
"m4": "GTGTA"
}
[70]:
seq_len = 50
# create backgrounds, here we care about only the actual sequences for illustrative purposes
backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet="ACGT",
b_alphabet_prior=[0.25, 0.25, 0.25, 0.25],
number_of_backgrounds=30,
length_of_backgrounds_min=seq_len),
reader=shared_reader,
writer=inmotifin.Writer(workdir=".", title="group_loc_sim"),
rng=rng)
backgrounds, _ = backgrounder.simulate_iid_backgrounds()
[71]:
num_sequences = 30
group_per_seq = 2
freq_sampler = inmotifin.FrequencySampler(
frequencies=frequencies,
num_groups_per_seq=group_per_seq,
rng=rng)
inserter = inmotifin.Inserter(to_replace=False)
[72]:
final_seq = {}
final_pos = {}
for seq_idx in range(num_sequences):
group_set = freq_sampler.select_groups()
# if the groups are the same, select motifs together and assign a single mean location
if len(set(group_set)) == 1:
seqid = str(seq_idx) + "_single_group"
motifs = test_freq.select_motifs_from_groups(
group_ids=selected_groups,
num_instances_per_seq=4,
w_replacement=False)
instance_seq = [motif_instances[motif_id] for motif_id in motifs]
position_means = [rng.uniform(10, 40)]
position_vars = [1]
positioner = inmotifin.Positioner(
params=inmotifin.PositionParams(
position_type="gaussian",
position_means=position_means,
position_variances=position_vars,
to_replace=False),
selected_instances=instance_seq,
seq_length=seq_len,
reader=shared_reader,
rng=rng
)
positions = positioner.select_positions().positions
final_seq[seqid] = inserter.generate_motif_in_sequence(
sequence=backgrounds["group_loc_sim_seq_" + str(seq_idx)],
motif_instances=instance_seq,
positions=positions
)
final_pos[seqid] = positions
else:
# Otherwise, sample motifs separately and sample location for each group
seqid = str(seq_idx) + "_multi_group"
positions = []
instance_seqs = []
for group in group_set:
motifs = test_freq.select_motifs_from_groups(
group_ids=[group],
num_instances_per_seq=2,
w_replacement=False)
instance_seq = [motif_instances[motif_id] for motif_id in motifs]
instance_seqs.extend(instance_seq)
position_means = [rng.uniform(10, 40)]
position_vars = [1]
positioner = inmotifin.Positioner(
params=inmotifin.PositionParams(
position_type="gaussian",
position_means=position_means,
position_variances=position_vars,
to_replace=False),
selected_instances=instance_seq,
seq_length=seq_len,
reader=shared_reader,
rng=rng
)
pos = positioner.select_positions().positions
positions.extend(pos)
final_seq[seqid] = inserter.generate_motif_in_sequence(
sequence=backgrounds["group_loc_sim_seq_" + str(seq_idx)],
motif_instances=instance_seqs,
positions=positions
)
final_pos[seqid] = positions
[73]:
print_limit = 5
for seqkey, seqvalue in final_seq.items():
print(seqkey)
print(final_pos[seqkey])
print(seqvalue)
print_limit -= 1
if print_limit == 0:
break
0_single_group
[(12, 12), (12, 12), (12, 12), (10, 10)]
AACCACACGCAAAATGCCCCCCGTGTACTCTGCCACGTCCGCGACGGCCATACCTTCTCTTGAAC
1_multi_group
[(30, 30), (29, 29), (24, 24), (23, 23)]
ATAAGCTACGTCGAGCAACCGGGAAAACAAAATGGGACCCATTTTCGCAGGAATGATACTATAAT
2_single_group
[(40, 40), (40, 40), (40, 40), (38, 38)]
TCACACGCGTCATTATCAATATACAGCCTCGTGTGAGAAAAAATAAAAGTGTATTTTCCTCCTTTCA
3_multi_group
[(33, 33), (32, 32), (17, 17), (17, 17)]
AAACTACCCACTTCCCCAAAAAAAAGGCAGCTCAGTCTAACCCCTTTTCTTGGGTAGTTTTAAAG
4_multi_group
[(38, 38), (37, 37), (17, 17), (14, 14)]
CACCGTCTGCTATGAAAATAAAAAACAACTTATAAGATCATCTCAAAAAACCCAACATGCTGGGC
Remove inserted motif instances by masking them with random short backgrounds
[74]:
controller = inmotifin.Controller(
basic_params=inmotifin.BasicParams(
title="masktest",
workdir=".",
seed=47))
seq_with_motif = {
"seq0": "AAAAAGCGA",
"seq1": "CAACCCCCC",
"seq2": "TTTGATTCC"}
seq_with_motif_prob = {
"seq0": np.concatenate((
np.tile([1, 0, 0, 0], (5, 1)),
np.tile([0, 0.1, 0.9, 0], (3, 1)),
np.tile([1, 0, 0, 0], (1, 1))
)),
"seq1": np.concatenate((
np.tile([0, 1, 0, 0], (1, 1)),
np.tile([0.9, 0.1, 0, 0], (3, 1)),
np.tile([0, 1, 0, 0], (5, 1))
)),
"seq2": np.concatenate((
np.tile([0, 0, 0, 1], (3, 1)),
np.tile([0.5, 0, 0.5, 0], (2, 1)),
np.tile([0, 0, 0, 1], (2, 1)),
np.tile([0, 1, 0, 0], (2, 1))
))}
positions = {
"seq0": [(5, 7)],
"seq1": [(1, 3)],
"seq2": [(3, 4), (7, 8)]}
mask_alphabet = "ACGT"
mask_alphabet_prior = [0, 0, 0.3, 0.7]
masked_seq, masked_prob = controller.mask_motif_in_seq(
seq_with_motif=seq_with_motif,
positions=positions,
mask_alphabet=mask_alphabet,
mask_alphabet_prior=mask_alphabet_prior,
seq_with_motif_prob=seq_with_motif_prob)
[75]:
masked_seq
[75]:
{'seq0_masked': 'AAAAATTTA',
'seq1_masked': 'CGTTCCCCC',
'seq2_masked': 'TTTGTTTTG'}
[76]:
masked_prob
[76]:
{'seq0_masked': array([[1. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. ],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7],
[1. , 0. , 0. , 0. ]]),
'seq1_masked': array([[0. , 1. , 0. , 0. ],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0. ]]),
'seq2_masked': array([[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0.3, 0.7],
[0. , 0. , 0.3, 0.7]])}
Simulating sequences with COBIND-predicted motif pairs
We have run COBIND pipeline using in vivo SOX17 and SOX2 binding sites as anchors (see manuscript for more details on this research). The pipeline discovers co-binding patterns. We can take the discovered motifs and information about spacing between the anchor (core) and co-binding motifs and inMOTIFin to create multimer motifs and then insert them in random background sequences.
Getting COBIND-predicted motif pairs and their grammar
We first need to get the core and co-binder motif pairs and the spacing information from COBIND output.
[77]:
# Reading txt files as numpy arrays, skipping non-numeric lines
def read_motif_matrix(path):
with open(path, "r") as f:
lines = f.readlines()
numeric_lines = []
for line in lines:
parts = line.strip().split()
if parts and all(p.replace('.', '', 1).replace('-', '', 1).isdigit() for p in parts):
numeric_lines.append(line)
if numeric_lines:
return np.loadtxt(numeric_lines)
else:
return None
# Reading motif txt files directly with normalization
def normalize_motif_matrix(matrix):
"""Normalize each row to sum exactly to 1.0"""
if matrix is None:
return None
# Normalize each row by dividing by its sum
row_sums = np.sum(matrix, axis=1, keepdims=True)
# Avoid division by zero
row_sums[row_sums == 0] = 1
return matrix / row_sums
# Reading spacings summary files
files = glob.glob("cobind_for_inmotifin/results/clustering_results/*/spacings/spacings_summary.tab")
dfs = []
for f in files:
tf_name = os.path.basename(os.path.dirname(os.path.dirname(f)))
df = pd.read_csv(f, sep="\t")
df["TF"] = tf_name
dfs.append(df)
spacings_df = pd.concat(dfs, ignore_index=True)
selected_columns = ["TF", "Spacer_length", "Location", "Subcluster", "Core_logo", "Cobinder_logo"]
spacings_selected = spacings_df[selected_columns].drop_duplicates()
spacings_selected
cobind_motif_dict = {}
for _, row in spacings_selected.iterrows():
core_path = row["Core_logo"].replace(".png", ".txt")
cobinder_path = row["Cobinder_logo"].replace(".png", ".txt")
core_key = f"{row['TF']}:{row['Spacer_length']}:{row['Location']}:core"
cobinder_key = f"{row['TF']}:{row['Spacer_length']}:{row['Location']}:cobinder"
core_motif = read_motif_matrix(core_path)
cobind_motif_dict[core_key] = normalize_motif_matrix(core_motif)
cobinder_motif = read_motif_matrix(cobinder_path)
cobind_motif_dict[cobinder_key] = normalize_motif_matrix(cobinder_motif)
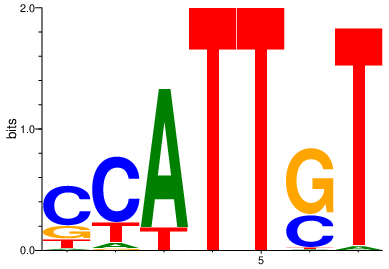
cobind_motif_dict["SOX17:0:right:core"]
[77]:
array([[0.031458 , 0.611535 , 0.209742 , 0.147265 ],
[0.066923 , 0.694946 , 0.023109 , 0.215022 ],
[0.845159 , 0. , 0.00788 , 0.146961 ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0.01902302, 0.31293631, 0.64596165, 0.02207902],
[0.025962 , 0. , 0. , 0.974038 ]])
[78]:
# We select SOX17 anchor and its cobinder motifs for demonstration
sox17_core = 'SOX17:0:right:core'
sox17_cobinder = 'SOX17:0:right:cobinder'
[79]:
core = seqlogo.Ppm(cobind_motif_dict[sox17_core])
seqlogo.seqlogo(core, ic_scale = True, format = 'png', size = 'small')
[79]:
[80]:
cobinder = seqlogo.Ppm(cobind_motif_dict[sox17_cobinder])
seqlogo.seqlogo(cobinder, ic_scale = True, format = 'png', size = 'small')
[80]:

Creating multimeric motifs using COBIND motifs
We can use two COBIND motifs, known anchor and predicted co-binding patter, and spacing information to create multimer motif with inMOTIFin.
We will continue using SOX17 and its co-binding motif (which was predicted to be OCT4) for this and further demonstrations.
[81]:
cobind_motif_writer = inmotifin.Writer(workdir="cobind_for_inmotifin", title="multimer_sim")
cobind_rng = np.random.default_rng(seed=42)
cobind_multimerer = inmotifin.Multimerer(
params=inmotifin.MultimerParams(
motif_files=None,
multimerisation_rule_path=None),
reader=shared_reader,
writer=cobind_motif_writer,
rng=cobind_rng)
[82]:
cobind_dimers = inmotifin.Motifs(
motifs=cobind_motif_dict,
alphabet='ACGT',
alphabet_revcomp_pairs=None)
cobind_multimerer.motifs = cobind_dimers
cobind_multimerer.alphabet = "ACGT"
[83]:
SOX17_OCT4_dimer = cobind_multimerer.create_a_multimer(
motifs=[cobind_motif_dict[sox17_core], cobind_motif_dict[sox17_cobinder]],
distances=[0])
SOX17_OCT4_dimer = {"SOX17_OCT4": SOX17_OCT4_dimer}
SOX17_OCT4_dimer_logo = seqlogo.Ppm(SOX17_OCT4_dimer['SOX17_OCT4'])
Sometimes ghostsript is broken for seqlogos. This is a workaround below:
[84]:
import logomaker
import matplotlib.pyplot as plt
n_symbols = len(SOX17_OCT4_dimer_logo.alphabet)
eps = 1e-10
IC_per_position = np.log2(n_symbols) + np.sum(
SOX17_OCT4_dimer_logo.ppm * np.log2(SOX17_OCT4_dimer_logo.ppm + eps), axis=1)
plt.figure(figsize=(8, 3))
logomaker.Logo(
pd.DataFrame(
SOX17_OCT4_dimer_logo.ppm.mul(IC_per_position, axis=0),
columns=list(SOX17_OCT4_dimer_logo.alphabet)),\
shade_below=0.5, fade_below=0.5)
plt.title("SOX17-OCT4 Dimer")
plt.tight_layout()
plt.show
[84]:
<function matplotlib.pyplot.show(close=None, block=None)>
<Figure size 800x300 with 0 Axes>
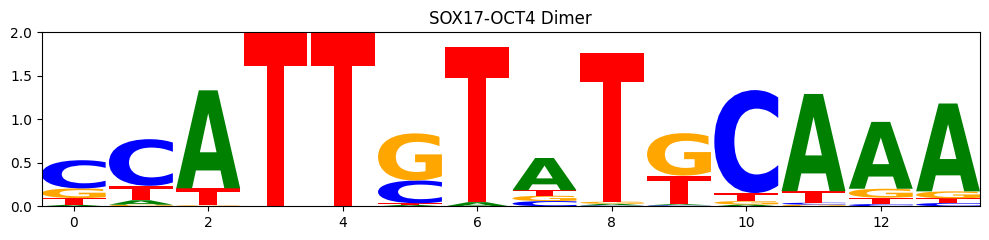
[85]:
# Adding generated dimer motif to all COBIND motifs
cobind_motif_dict["SOX17_OCT4"] = SOX17_OCT4_dimer["SOX17_OCT4"]
cobind_motif_dict["SOX17:0:right:core"]
[85]:
array([[0.031458 , 0.611535 , 0.209742 , 0.147265 ],
[0.066923 , 0.694946 , 0.023109 , 0.215022 ],
[0.845159 , 0. , 0.00788 , 0.146961 ],
[0. , 0. , 0. , 1. ],
[0. , 0. , 0. , 1. ],
[0.01902302, 0.31293631, 0.64596165, 0.02207902],
[0.025962 , 0. , 0. , 0.974038 ]])
[86]:
# Exporting motifs to meme format:
cobind_motif_writer.motif_to_meme(
motifs=cobind_motif_dict,
alphabet='ACGT',
file_prefix="COBIND_motifs")
Generating random background sequences for COBIND dimer insertion
We can use inMOTIFin functionalities to generate random backgrounds (as shown above), which later can be used to insert a COBIND dimer.
[87]:
cobind_controller = inmotifin.Controller(
basic_params=inmotifin.BasicParams(
workdir="cobind_for_inmotifin",
title="controller_insertion",
seed=47))
alphabet = "ACGT"
alphabet_prior = np.array([0.2, 0.3, 0.3, 0.2])
cobind_backgrounder = inmotifin.Backgrounder(
params=inmotifin.BackgroundParams(
b_alphabet=alphabet,
b_alphabet_prior=alphabet_prior,
number_of_backgrounds=5,
length_of_backgrounds_min=50),
reader=shared_reader,
writer=inmotifin.Writer(workdir="cobind_for_inmotifin", title="background_sim"),
rng=cobind_rng)
cobind_backgrounds, _ = cobind_backgrounder.simulate_iid_backgrounds()
cobind_backgrounder.writer.dict_to_fasta(
seq_dict=cobind_backgrounds,
filename="cobind_backgrounds")
cobind_backgrounds
[87]:
{'background_sim_seq_0': 'GCTGATGGACCTGTCCGATGGCTTGACAAGGTCCCAACCGCTGCTTCCGA',
'background_sim_seq_1': 'AAGGGGCGAAGCGGGGGCACCCTCACCGGGGCTAAAGCAGAGCCCGCAAT',
'background_sim_seq_2': 'TGCTGGCCATCCCGATGGCGGGACACCAAGATGCGATCGACCTGCCCGCA',
'background_sim_seq_3': 'TTAGAGCGGGATCAGCTTCTCGCTAACTTGTTGCGGCAGCTCATAAGTAC',
'background_sim_seq_4': 'GTGAACAGAGGGATGGAATCCCGTCTAGGAACTGTTCGAATGCGGTGCCC'}
[88]:
cobind_backgrounder.writer.dict_to_fasta(
seq_dict=cobind_backgrounds,
filename="cobind_backgrounds")
Inserting COBIND motifs into random backgrounds
Now with the motifs and backgrounds, we can generate simulated sequences with motif instances, based on biological knowledge.
[89]:
cobind_motif_ids = [
["SOX17_OCT4"],
["SOX17:0:right:core"],
["SOX17:0:right:core", "SOX17:0:right:cobinder"],
["SOX17_OCT4"],
["SOX17_OCT4"]
]
cobind_positions = [[(10, 25)], [(20, 28)], [(10, 18), (25, 33)], [(2, 17)], [(5, 20)]]
cobind_orientations = [[0], [0], [1, 1], [0], [1]]
cobind_b_alphabets = {bg_key: alphabet for bg_key, _ in cobind_backgrounds.items()}
cobind_background_ids = [bg_key for bg_key, _ in cobind_backgrounds.items()]
sequence_probs = {
bg_key: np.tile(alphabet_prior, (len(bg_seq), 1)) for bg_key, bg_seq in cobind_backgrounds.items()}
cobind_motifs_obj = inmotifin.Motifs(
motifs=cobind_motif_dict,
alphabet='ACGT',
alphabet_revcomp_pairs={'A': 'T', 'C': 'G', 'G': 'C', 'T': 'A'}
)
cobind_motif_in_sequences, cobind_probabilistic_motif_in_sequences = cobind_controller.create_motif_in_seq(
background_ids=cobind_background_ids,
background_dict=cobind_backgrounds,
b_alphabets=cobind_b_alphabets,
sequence_probs=sequence_probs,
positions=cobind_positions,
motif_ids=cobind_motif_ids,
motifs=cobind_motifs_obj,
orientations=cobind_orientations)
[90]:
cobind_motif_in_sequences
[90]:
{'background_sim_seq_0_SOX17_OCT4_10:25_0': 'GCTGATGGACTTTGCACACAATACGACAAGGTCCCAACCGCTGCTTCCGA',
'background_sim_seq_1_SOX17:0:right:core_20:28_0': 'AAGGGGCGAAGCGGGGGCACTCAATGAGGGGCTAAAGCAGAGCCCGCAAT',
'background_sim_seq_2_SOX17:0:right:core_SOX17:0:right:cobinder_10:18_25:33_1_1': 'TGCTGGCCATGGTTTGTGCGGGACATTGCAAAGCGATCGACCTGCCCGCA',
'background_sim_seq_3_SOX17_OCT4_2:17_0': 'TTTATGCATAGAAATGTTCTCGCTAACTTGTTGCGGCAGCTCATAAGTAC',
'background_sim_seq_4_SOX17_OCT4_5:20_1': 'GTGAAGCATTGTATGCGTACCCGTCTAGGAACTGTTCGAATGCGGTGCCC'}
[91]:
cobind_probabilistic_motif_in_sequences["background_sim_seq_0_SOX17_OCT4_10:25_0"]
[91]:
array([[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.04549095, 0.06756593, 0.03213597, 0.85480715],
[0.075684 , 0.105387 , 0.026675 , 0.792254 ],
[0.1027001 , 0.01445901, 0.01755902, 0.86528187],
[0.06895607, 0.02947803, 0.88603489, 0.01553102],
[0.391595 , 0.580054 , 0.013386 , 0.014965 ],
[0.969974 , 0.013709 , 0.005576 , 0.010741 ],
[0.114354 , 0.110361 , 0.10803 , 0.667255 ],
[0.974038 , 0. , 0. , 0.025962 ],
[0.02207902, 0.64596165, 0.31293631, 0.01902302],
[1. , 0. , 0. , 0. ],
[1. , 0. , 0. , 0. ],
[0.146961 , 0.00788 , 0. , 0.845159 ],
[0.215022 , 0.023109 , 0.694946 , 0.066923 ],
[0.147265 , 0.209742 , 0.611535 , 0.031458 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ],
[0.2 , 0.3 , 0.3 , 0.2 ]])
[92]:
cobind_controller.writer.dict_to_fasta(
seq_dict=cobind_motif_in_sequences,
filename="cobind_motif_in_seq")
cobind_controller.writer.save_dictionary_with_numpy_to_npz(
numpy_dict=cobind_probabilistic_motif_in_sequences,
filename="cobind_probabilistic_motif_in_seq")